SQL vs. NoSQL
SQL
SQL was initially created to be the language for generating, manipulating, and retrieving data from relational databases, which have been around for more than 40 years. Over the past decade or so, however, other data platforms such as Hadoop, Spark, and NoSQL have gained a great deal of traction, eating away at the relational database market. However, the SQL language has been evolving to facilitate the retrieval of data from various platforms, regardless of whether the data is stored in tables, documents, or flat files.
Whether you will be using a relational database or not, if you are working in data engineering, business intelligence, or some other facet of data analysis, you will likely need to know SQL, along with other languages/platforms such as Python and R. Data is everywhere, in huge quantities, and arriving at a rapid pace, and people who can extract meaningful information from all this data are in big demand.
Aggregation, Grouping, Ordering & Filtering
The aggregation functions perform calculations on multiple rows and return the result as one value, collapsing the individual rows in the process. When an aggregation function is used, you need to group the data on fields which are not aggregated by using a GROUP BY clause.
Filtering is used when you need to extract a subset of data by using a specific condition. You can use WHERE and HAVING clauses to filter the data as per your needs.
Joins and Unions
Data Engineers are typically responsible for collating different data sources together and providing a cleaner source of information for the Data Scientists or Data Analysts. In order to collate data from different sources, they need a good understanding of SQL Joins and Unions.
CTEs, Sub Queries, and Window Functions
As the queries become more complex, it’s not always possible to write a single query and do all the analysis. Sometimes, it’s necessary to create a temporary table and use the results in a new query to perform analysis at different levels. We can use a subquery, a CTE (Common Table Expression), or a TEMP (Temporary) table for this. As a Data Engineer, you need to understand these concepts to write better and optimized SQL queries.
Command Categories
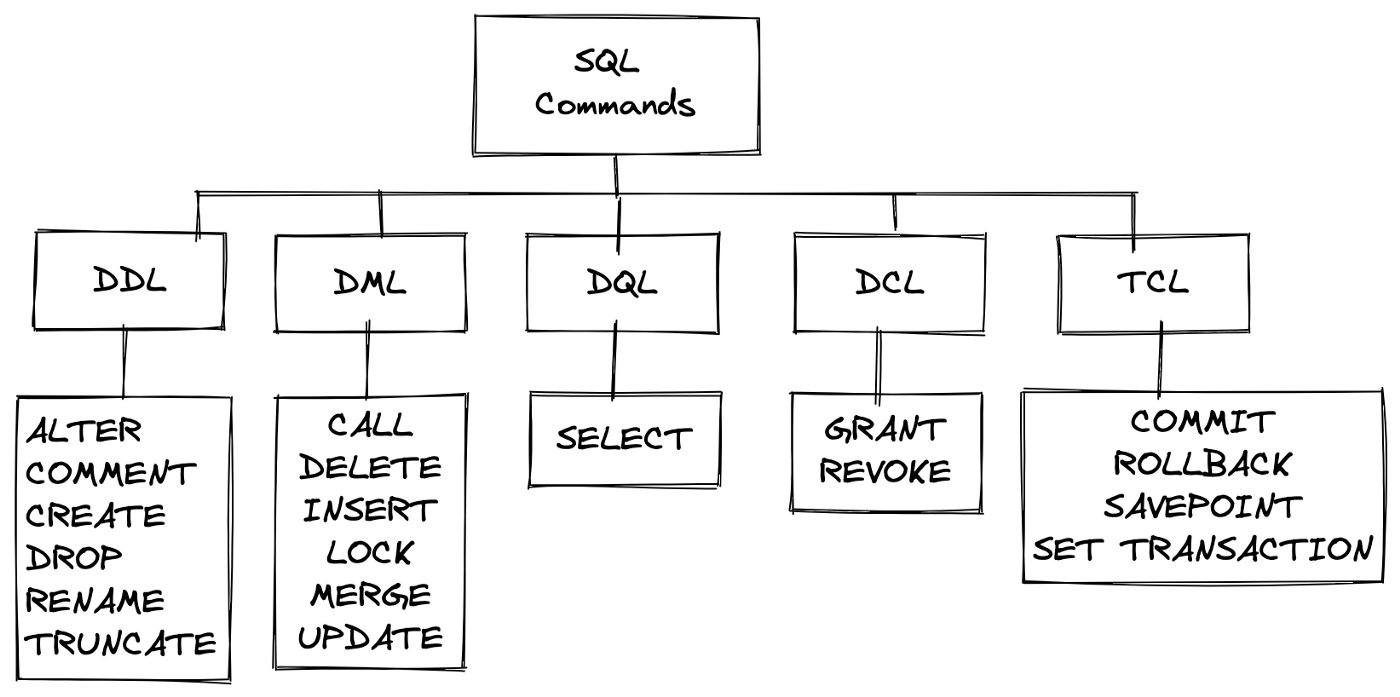
Query breakdown
| Statement | How to Use It | Other Details |
|---|---|---|
| SELECT | SELECT Col1, Col2, ... | Provide the columns you want |
| FROM | FROM Table | Provide the table where the columns exist |
| LIMIT | LIMIT 10 | Limits based number of rows returned |
| ORDER BY | ORDER BY Col | Orders table based on the column. Used with DESC. |
| WHERE | WHERE Col > 5 | A conditional statement to filter your results |
| LIKE | WHERE Col LIKE '%me%' | Only pulls rows where column has 'me' within the text |
| IN | WHERE Col IN ('Y', 'N') | A filter for only rows with column of 'Y' or 'N' |
| NOT | WHERE Col NOT IN ('Y', 'N') | NOT is frequently used with LIKE and IN |
| AND | WHERE Col1 > 5 AND Col2 < 3 | Filter rows where two or more conditions must be true |
| OR | WHERE Col1 > 5 OR Col2 < 3 | Filter rows where at least one condition must be true |
| BETWEEN | WHERE Col BETWEEN 3 AND 5 | Often easier syntax than using an AND |
Common types of NoSQL
Key-value stores
- Array of key-value pairs. The "key" is an attribute name.
- Redis, Vodemort, Dynamo.
Document databases
- Data is stored in documents.
- Documents are grouped in collections.
- Each document can have an entirely different structure.
- CouchDB, MongoDB.
Wide-column / columnar databases
- Column families - containers for rows.
- No need to know all the columns up front.
- Each row can have different number of columns.
- Cassandra, HBase.
Graph database
- Data is stored in graph structures
- Nodes: entities
- Properties: information about the entities
- Lines: connections between the entities
- Neo4J, InfiniteGraph
Differences between SQL and NoSQL
Storage
- SQL: store data in tables.
- NoSQL: have different data storage models.
Schema
- SQL
- Each record conforms to a fixed schema.
- Schema can be altered, but it requires modifying the whole database.
- NoSQL:
- Schemas are dynamic.
Querying
- SQL
- Use SQL (structured query language) for defining and manipulating the data.
- NoSQL
- Queries are focused on a collection of documents.
- UnQL (unstructured query language).
- Different databases have different syntax.
Scalability
- SQL
- Vertically scalable (by increasing the horsepower: memory, CPU, etc) and expensive.
- Horizontally scalable (across multiple servers); but it can be challenging and time-consuming.
- NoSQL
- Horizontablly scalable (by adding more servers) and cheap.
ACID
- Atomicity, consistency, isolation, durability
- SQL
- ACID compliant
- Data reliability
- Gurantee of transactions
- NoSQL
- Most sacrifice ACID compliance for performance and scalability.
Which one to use?
SQL
- Ensure ACID compliance.
- Reduce anomalies.
- Protect database integrity.
- Data is structured and unchanging.
NoSQL
- Data has little or no structure.
- Make the most of cloud computing and storage.
- Cloud-based storage requires data to be easily spread across multiple servers to scale up.
- Rapid development.
- Frequent updates to the data structure.
Resources
- SQL Cheat Sheet
- What I realized after solving 100 leetcode SQL questions
- Udacity Nanodegree on SQL
- SQL Leetcode All questions set
- LeetCode SQL Problem Solving Questions With Solutions
- HackerRank SQL Problem Solving Questions With Solutions
- SQL Interview Questions
- Data Engineer Interview Questions
- SQL Case Studies
- SQL Commands Categories
- 10 SQL Queries You Should Know as a Data Engineer
- SQL JOIN Interview Questions
- The Ultimate Guide to SQL Window Functions
{kind=link}