Apache Spark
Apache Spark is an Open source analytical processing engine for large scale powerful distributed data processing and machine learning applications. Spark is Originally developed at the University of California, Berkeley’s, and later donated to Apache Software Foundation. In February 2014, Spark became a Top-Level Apache Project and has been contributed by thousands of engineers and made Spark one of the most active open-source projects in Apache.
Apache Spark is a framework that is supported in Scala, Python, R Programming, and Java. Below are different implementations of Spark.
- Spark – Default interface for Scala and Java
- PySpark – Python interface for Spark
- SparklyR – R interface for Spark.
Features:
- In-memory computation
- Distributed processing using parallelize
- Can be used with many cluster managers (Spark, Yarn, Mesos e.t.c)
- Fault-tolerant
- Immutable
- Lazy evaluation
- Cache & persistence
- Inbuild-optimization when using DataFrames
- Supports ANSI SQL
Advantages:
- Spark is a general-purpose, in-memory, fault-tolerant, distributed processing engine that allows you to process data efficiently in a distributed fashion.
- Applications running on Spark are 100x faster than traditional systems.
- You will get great benefits using Spark for data ingestion pipelines.
- Using Spark we can process data from Hadoop HDFS, AWS S3, Databricks DBFS, Azure Blob Storage, and many file systems.
- Spark also is used to process real-time data using Streaming and Kafka.
- Using Spark Streaming you can also stream files from the file system and also stream from the socket.
- Spark natively has machine learning and graph libraries.
The Genesis of Spark
Big Data and Distributed Computing at Google
When we think of scale, we can’t help but think of the ability of Google’s search engine to index and search the world’s data on the internet at lightning speed. The name Google is synonymous with scale. In fact, Google is a deliberate misspelling of the mathematical term googol: that’s 1 plus 100 zeros!
Neither traditional storage systems such as relational database management systems (RDBMSs) nor imperative ways of programming were able to handle the scale at which Google wanted to build and search the internet’s indexed documents. The resulting need for new approaches led to the creation of the Google File System (GFS), MapReduce (MR), and Bigtable.
While GFS provided a fault-tolerant and distributed filesystem across many commodity hardware servers in a cluster farm, Bigtable offered scalable storage of structured data across GFS. MR introduced a new parallel programming paradigm, based on functional programming, for large-scale processing of data distributed over GFS and Bigtable.
In essence, your MR applications interact with the MapReduce system that sends computation code (map and reduce functions) to where the data resides, favoring data locality and cluster rack affinity rather than bringing data to your application.
The workers in the cluster aggregate and reduce the intermediate computations and produce a final appended output from the reduce function, which is then written to a distributed storage where it is accessible to your application. This approach significantly reduces network traffic and keeps most of the input/output (I/O) local to disk rather than distributing it over the network.
Most of the work Google did was proprietary, but the ideas expressed in the aforementioned three papers spurred innovative ideas elsewhere in the open source community—especially at Yahoo!, which was dealing with similar big data challenges of scale for its search engine.
Hadoop at Yahoo!
The computational challenges and solutions expressed in Google’s GFS paper provided a blueprint for the Hadoop File System (HDFS), including the MapReduce implementation as a framework for distributed computing. Donated to the Apache Software Foundation (ASF), a vendor-neutral non-profit organization, in April 2006, it became part of the Apache Hadoop framework of related modules: Hadoop Common, MapReduce, HDFS, and Apache Hadoop YARN.
Although Apache Hadoop had garnered widespread adoption outside Yahoo!, inspiring a large open source community of contributors and two open source–based commercial companies (Cloudera and Hortonworks, now merged), the MapReduce framework on HDFS had a few shortcomings.
First, it was hard to manage and administer, with cumbersome operational complexity. Second, its general batch-processing MapReduce API was verbose and required a lot of boilerplate setup code, with brittle fault tolerance. Third, with large batches of data jobs with many pairs of MR tasks, each pair’s intermediate computed result is written to the local disk for the subsequent stage of its operation. This repeated performance of disk I/O took its toll: large MR jobs could run for hours on end, or even days.
And finally, even though Hadoop MR was conducive to large-scale jobs for general batch processing, it fell short for combining other workloads such as machine learning, streaming, or interactive SQL-like queries.
To handle these new workloads, engineers developed bespoke systems (Apache Hive, Apache Storm, Apache Impala, Apache Giraph, Apache Drill, Apache Mahout, etc.), each with their own APIs and cluster configurations, further adding to the operational complexity of Hadoop and the steep learning curve for developers.
The question then became (bearing in mind Alan Kay’s adage, “Simple things should be simple, complex things should be possible”), was there a way to make Hadoop and MR simpler and faster?
Spark’s Early Years at AMPLab
Researchers at UC Berkeley who had previously worked on Hadoop MapReduce took on this challenge with a project they called Spark. They acknowledged that MR was inefficient (or intractable) for interactive or iterative computing jobs and a complex framework to learn, so from the onset they embraced the idea of making Spark simpler, faster, and easier. This endeavor started in 2009 at the RAD Lab, which later became the AMPLab (and now is known as the RISELab).
Early papers published on Spark demonstrated that it was 10 to 20 times faster than Hadoop MapReduce for certain jobs. Today, it’s many orders of magnitude faster. The central thrust of the Spark project was to bring in ideas borrowed from Hadoop MapReduce, but to enhance the system: make it highly fault tolerant and embarrassingly parallel, support in-memory storage for intermediate results between iterative and interactive map and reduce computations, offer easy and composable APIs in multiple languages as a programming model, and support other workloads in a unified manner. We’ll come back to this idea of unification shortly, as it’s an important theme in Spark.
By 2013 Spark had gained widespread use, and some of its original creators and researchers—Matei Zaharia, Ali Ghodsi, Reynold Xin, Patrick Wendell, Ion Stoica, and Andy Konwinski—donated the Spark project to the ASF and formed a company called Databricks.
Databricks and the community of open source developers worked to release Apache Spark 1.0 in May 2014, under the governance of the ASF. This first major release established the momentum for frequent future releases and contributions of notable features to Apache Spark from Databricks and over 100 commercial vendors.
What is Apache Spark?
Spark is a distributed data processing engine meaning its components work collaboratively on a cluster of machines to run your tasks. It can be run on a single machine (standalone mode) as well for testing purposes. Spark is an open-source project that was originally developed in 2009 by Matei Zaharia as a replacement/alternative to MapReduce.
Watch this video:
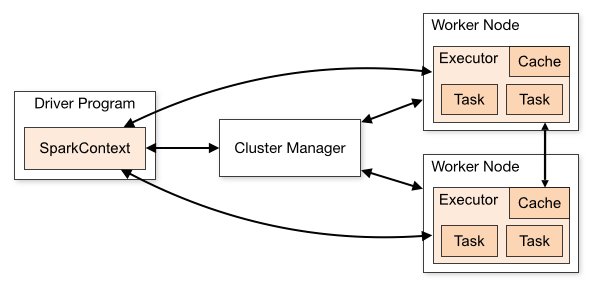
When would you need Apache Spark?
It was designed for large-scale data processing ETLs, streaming pipelines, and complex data exploration activities. It can be integrated with a wide range of databases and technologies such as HDFS, JDBC, MongoDB, Kafka, and more! It supports different data formats such as Parquet (recommended), ORC, CSV.
It was designed to be developer-friendly. You can use your favorite programming language: Python, Scala, R, and you can even run SQL-like queries!
It is a unified stack that offers Speed, Ease of Use, Modularity, and Extensibility.
Data engineers use Spark because it provides a simple way to parallelize computations and hides all the complexity of distribution and fault tolerance. This leaves them free to focus on using high-level DataFrame-based APIs and domain-specific language (DSL) queries to do ETL, reading and combining data from multiple sources.
The performance improvements in Spark 2.x and Spark 3.0, due to the Catalyst optimizer for SQL and Tungsten for compact code generation, have made life for data engineers much easier. They can choose to use any of the three Spark APIs—RDDs, DataFrames, or Datasets—that suit the task at hand, and reap the benefits of Spark.
Hadoop vs Spark
What is Hadoop
Apache Hadoop is an open source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data. Instead of using one large computer to store and process the data, Hadoop allows clustering multiple computers to analyze massive datasets in parallel more quickly.
Hadoop consists of four main modules:
- Hadoop Distributed File System (HDFS) – A distributed file system that runs on standard or low-end hardware. HDFS provides better data throughput than traditional file systems, in addition to high fault tolerance and native support of large datasets.
- Yet Another Resource Negotiator (YARN) – Manages and monitors cluster nodes and resource usage. It schedules jobs and tasks.
- MapReduce – A framework that helps programs do the parallel computation on data. The map task takes input data and converts it into a dataset that can be computed in key value pairs. The output of the map task is consumed by reduce tasks to aggregate output and provide the desired result.
- Hadoop Common – Provides common Java libraries that can be used across all modules.
Hadoop makes it easier to use all the storage and processing capacity in cluster servers, and to execute distributed processes against huge amounts of data. Hadoop provides the building blocks on which other services and applications can be built.
Applications that collect data in various formats can place data into the Hadoop cluster by using an API operation to connect to the NameNode. The NameNode tracks the file directory structure and placement of “chunks” for each file, replicated across DataNodes. To run a job to query the data, provide a MapReduce job made up of many map and reduce tasks that run against the data in HDFS spread across the DataNodes. Map tasks run on each node against the input files supplied, and reducers run to aggregate and organize the final output.
The Hadoop ecosystem has grown significantly over the years due to its extensibility. Today, the Hadoop ecosystem includes many tools and applications to help collect, store, process, analyze, and manage big data. Some of the most popular applications are:
- Spark – An open source, distributed processing system commonly used for big data workloads. Apache Spark uses in-memory caching and optimized execution for fast performance, and it supports general batch processing, streaming analytics, machine learning, graph databases, and ad hoc queries.
- Presto – An open source, distributed SQL query engine optimized for low-latency, ad-hoc analysis of data. It supports the ANSI SQL standard, including complex queries, aggregations, joins, and window functions. Presto can process data from multiple data sources including the Hadoop Distributed File System (HDFS) and Amazon S3.
- Hive – Allows users to leverage Hadoop MapReduce using a SQL interface, enabling analytics at a massive scale, in addition to distributed and fault-tolerant data warehousing.
- HBase – An open source, non-relational, versioned database that runs on top of Amazon S3 (using EMRFS) or the Hadoop Distributed File System (HDFS). HBase is a massively scalable, distributed big data store built for random, strictly consistent, real-time access for tables with billions of rows and millions of columns.
- Zeppelin – An interactive notebook that enables interactive data exploration.
Apache Hadoop on Amazon EMR
Amazon EMR is a managed service that lets you process and analyze large datasets using the latest versions of big data processing frameworks such as Apache Hadoop, Spark, HBase, and Presto on fully customizable clusters.
Elastic MapReduce, or EMR, is Amazon Web Services’ solution for managing prepackaged Hadoop clusters and running jobs on them. You can work with regular MapReduce jobs or Apache Spark jobs, and can use Apache Hive, Apache Pig, Apache HBase, and some third-party applications. Scripting hooks enable the installation of additional services. Data is typically stored in Amazon S3 or Amazon DynamoDB.
The normal mode of operation for EMR is to define the parameters for a cluster, such as its size, location, Hadoop version, and variety of services, point to where data should be read from and written to, and define steps to execute such as MapReduce or Spark jobs. EMR launches a cluster, performs the steps to generate the output data, and then tears the cluster down. However, you can leave clusters running for further use, and even resize them for greater capacity or a smaller footprint.
EMR provides an API so that you can automate the launching and management of Hadoop clusters.
Follow this blog for more information.
Hadoop vs Spark
PySpark Cheat Sheet

More Resources
- Getting Started with Apache Spark
- Spark Interview Questions
- Hadoop and Spark Hands-on Practical Exercises
- Spark Quiz & Solution [Videos]
- Electricity Data processing with PySpark
- Distributed Computing and the difference between Hadoop and Spark
- igfasouza.com/blog/what-is-apache-spark
- 2003–2023: A Brief History of Big Data