Data Lakes and Lakehouses
Before the cloud data lake architecture
To understand how cloud data lakes help with the growing data needs of an organization, its important for us to first understand how data processing and insights worked a few decades ago. Businesses often thought of data as something that supplemented a business problem that needs to be solved. The approach was business problem centric, and involved the following steps :-
- Identify the problem to be solved.
- Define a structure for data that can help solve the problem.
- Collect or generate the data that adheres with the structure.
- Store the data in an Online Transaction Processing (OLTP) database, such as SQL Servers.
- Use another set of transformations (filtering, aggregations etc) to store data in Online Analytics Processing (OLAP) databases, SQL servers are used here as well.
- Build dashboards and queries from these OLAP databases to solve your business problem.
For instance, when an organization wanted to understand the sales, they built an application for sales people to input their leads, customers, and engagements, along with the sales data, and this application was supported by one or more operational databases.For example, there could be one database storing customer information, another storing employee information for the sales force, and a third database that stored the sales information that referenced both the customer and the employee databases. On-premises (referred to as on-prem) have three layers:
- Enterprise data warehouse - this is the component where the data is stored. It contains a database component to store the data, and a metadata component to describe the data stored in the database.
- Data marts - data marts are a segment of the enteprise data warehouse, that contain a business/topic focused databases that have data ready to serve the application. Data in the warehouse goes through another set of transformations to be stored in the data marts.
- Consumption/BI layer - this consists of the various visualization and query tools that are used by BI analysts to query the data in the data marts (or the warehouse) to generate insights.
Limitations of on-premises data warehouse solutions
While this works well for providing insights into the business, there are a few key limitations with this architecture, as listed below.
- Highly structured data: This architecture expects data to be highly structured every step of the way. As we saw in the examples above, this assumption is not realistic anymore, data can come from any source such as IoT sensors, social media feeds, video/audio files, and can be of any format (JSON, CSV, PNG, fill this list with all the formats you know), and in most cases, a strict structure cannot be enforced.
- Siloed data stores: There are multiple copies of the same data stored in data stores that are specialized for specific purposes. This proves to be a disadvantage because there is a high cost for storing these multiple copies of the same data, and the process of copying data back and forth is both expensive, error prone, and results in inconsistent versions of data across multiple data stores while the data is being copied.
- Hardware provisioning for peak utilization: On-premises data warehouses requires organizations to install and maintain the hardware required to run these services. When you expect bursts in demand (think of budget closing for the fiscal year or projecting more sales over the holidays), you need to plan ahead for this peak utilization and buy the hardware, even if it means that some of your hardware needs to be lying around underutilized for the rest of the time. This increases your total cost of ownership. Do note that this is specifically a limitation with respect on on-premises hardware rather than a difference between data warehouse vs data lake architecture.
What is a Cloud Data Lake Architecture
The big data scenarios go way beyond the confines of the traditional enterprise data warehouses. Cloud data lake architectures are designed to solve these exact problems, since they were designed to meet the needs of explosive growth of data and their sources, without making any assumptions on the source, the formats, the size, or the quality of the data. In contrast to the problem-first approach taken by traditional data warehouses, cloud data lakes take a data-first approach. In a cloud data lake architecture, all data is considered to be useful - either immediately or to meet a future need. And the first step in a cloud data architecture involves ingesting data in their raw, natural state, without any restrictions on the source, the size, or the format of the data. This data is stored in a cloud data lake, a storage system that is highly scalable and can store any kind of data. This raw data has variable quality and value, and needs more transformations to generate high value insights.
The processing systems on a cloud data lake work on the data that is stored in the data lake, and allow the data developer to define a schema on demand, i.e. describe the data at the time of processing. These processing systems then operate on the low value unstructured data to generate high value data, that is often structured, and contains meaningful insights. This high value structured data is then either loaded into an enterprise data warehouse for consumption, and can also be consumed directly from the data lake.
Watch this video:
Benefits of a Cloud Data Lake Architecture
At a high level, this cloud data lake architecture addresses the limitations of the traditional data warehouse architectures in the following ways:
- No restrictions on the data - As we saw, a data lake architecture consists of tools that are designed to ingest, store, and process all kinds of data without imposing any restrictions on the source, the size, or the structure of the data. In addition, these systems are designed to work with data that enters the data lake at any speed - real time data emitted continously as well as volumes of data ingested in batches on a scheduled basis. Further, the data lake storage is extremely low cost, so this lets us store all data by default without worrying about the bills. Think about how you would have needed to think twice before taking pictures with those film roll cameras, and these days click away without as much as a second thought with your phone cameras.
- Single storage layer with no silos - Note that in a cloud data lake architecture, your processing happens on data in the same store, where you don’t need specialized data stores for specialized purposes anymore. This not only lowers your cost, but also avoids errors involved in moving data back and forth across different storage systems.
- Flexibility of running diverse compute on the same data store - As you can see, a cloud data lake architecture inherently decouples compute and storage, so while the storage layer serves as a no-silos repository, you can run a variety of data processing computational tools on the same storage layer. As an example, you can leverage the same data storage layer to do data warehouse like business intelligence queries, advanced machine learning and data science computations, or even bespoke domain specific computations such as high performance computing like media processing or analysis of seismic data.
- Pay for what you use - Cloud services and tools are always designed to elastically scale up and scale down on demand, and you can also create and delete processing systems on demand, so this would mean that for those bursts in demand during holiday season or budget closing, you can choose to spin these systems up on demand without having them around for the rest of the year. This drastically reduces the total cost of ownership.
- Independently scale compute and storage - In a cloud data lake architecture, compute and storage are different types of resources, and they can be independently scaled, thereby allowing you to scale your resources depending on need. Storage systems on the cloud are very cheap, and enable you to store a large amount of data without breaking the bank. Compute resources are traditionally more expensive than storage, however, they do have the capability to be started or stopped on demand, thereby offering economy at scale.
Technically, it is possible to scale compute and storage independently in an on-premises Hadoop architecture as well. However, this involves careful consideration of hardware choices that are optimized specifically for compute and storage, and also have an optimized network connectivity. This is exactly what cloud providers offer with their cloud infrastructure services. Very few organizations have this kind of expertise, and explicitly choose to run their services on-premises.
This flexibility in processing all kinds of data in a cost efficient fashion helps organizations realize the value of data and turn them into valuable transformational insights.
Components of the cloud data lake architecture
There are four key components that create the foundation and serve as building blocks for the cloud data lake architecture. These components are:
- The data itself - structured, semi-structured and unstructured data
- The data lake storage - e.g. Amazon S3 (Simple Storage Service), Azure Data Lake Storage (ADLS) and Google Cloud Storage (GCS)
- The big data analytics engines that process the data - e.g. Apache Hadoop, Apache Spark and Real-time stream processing pipelines
- The cloud data warehouse - e.g. Amazon RedShift, Google BigQuery, Azure Synapse Analytics and Snowflake Data Platform
Modern Data Warehouse Architecture
In a modern data warehouse architecture, both the data lake and the data warehouse peacefully coexist, each serving a distinct purpose. The data lake serves as a low cost storage for a large amount of data and also supports exploratory scenarios such as data science and machine learning. The data warehouse stores high value data and is used to power dashboards used by the business and also is used for business intelligence users to query the highly structured data to gain insights about the business.
Data is first ingested into a data lake from various sources - on-premises databases, social media feeds, etc. This data is then transformed using big data analytics frameworks such as Hadoop and Spark, where multiple datasets can also be aggregated and filtered to generate high value structured data. This data is then loaded into a cloud data warehouse to power dashboards, as well as interactive dashboards for BI analysts using their very familiar tool of choice - SQL. In addition, the data lake also empowers a whole new set of scenarios that involve exploratory analysis by data scientists, and also machine learning models that can be fed back into their applications. A simplified representation of the modern data warehouse architecture is provided below:

There is now a question you would naturally ask here - what is the difference between using a cloud data warehouse directly, why is a data lake necessary in between? Specially, if I only have structured data, do I even need a data lake? If I can say so myself, these are great questions. There are a few reasons why you would need a data lake in this architecture.
- Data lakes cost a lot lesser than a data warehouse, and can act as your long term repository of data. It is of note to remember that data lakes are typically used to store large volumes of data (think tens or hundreds of petabytes) that the difference in cost is material.
- Data lakes support a variety of modern tools and frameworks around data science and machine learning, that you can enable completely new scenarios.
- Data lakes let you future-proof your design to scale to your growing needs. As an example, you might start off your initial data lake architecture to load data from your on-premises systems on a nightly basis and publish reports or dashboards for your business intelligence users, however, the same architecture is extensible to support real time data ingestion without having to rearchitect your solution.
- Data of all forms and structures are largely becoming relevant to organizations. Even if you are focused on structured data today, as you saw in the example above, you might find value in all kinds of data such as weather, social media feeds, etc.
Cloud adoption continues to grow with even highly regulated industries such as healthcare and Fintech embracing the cloud for cost-effective alternatives to keep pace with innovation; otherwise, they risk being left behind. People who have used security as the reason for not going to the cloud should be reminded that all the massive data breaches that have been splashing the media in recent years have all been from on-premises setups. Cloud architectures have more scrutiny and are in some ways more governed and secure.
Most enterprises currently have three types of data storage systems.
- Application Databases — Transactional systems which capture data from all operations in the enterprise e.g. HR, Finance, CRM, Sales etc.
- Data Lakes — These are catch-all cloud storage systems which store structured and unstructured data like application data backups, logs, web-click-streams, pictures, videos etc.
- Data Warehouses — Integrated, cleansed data organized in a way to enhance query performance so that we can run reports and dashboards quickly.
Benefits and Challenges of Modern Data Warehouse Architecture
The modern data warehouse has an important benefit of helping the business analysts leverage familiar Business Intelligence tool sets (SQL based) for consumption, while also enabling more modern scenarios around data science and machine learning that were originally not possible in their on-premises implementation of a data warehouse. This is primarily accomplished with a data lake, that serves as a no-silos data store supporting advanced data science and machine learning scenarios with cloud native services, while retaining the familiar data warehouse like SQL based interface for business intelligence users. In addition, the data administrators can isolate the access of the data to the data warehouse for the BI teams using familiar access control methods of the data warehouse. Their applications running on-premises can also be ported to the cloud over time to completely eliminate the need to maintain two sets of infrastructures. Further, the business is overall able to lower their costs by backing up the operational data into a data lake for a longer time period.
There are also a few challenges with this approach. The data engineers and administrators need to still maintain two sets of infrastructures - a data lake and data warehouse. The flexibility of storing all kinds of data in a data lake also poses a challenge - managing data in the data lake and assuming guarantees of data quality is a huge challenge that data engineers and data administrators now have to solve. They did not have this problem before. The data lake also runs the risk of growing into a data swamp if the data is not managed properly making your insights be hidden like a needle in a haystack. If BI users or business decision makers need new data sets, they need to rely upon the data engineers to process this data and load it into the warehouse, introducing a critical path. Further, if there is an interesting slice of data in the warehouse that the data scientists want to include for exploratory analysis, they need to load it back into the data lake, in a different data format, as well as a different data store, increasing the complexity of sharing.
Data Lakehouse Architecture
We have been collecting data for decades. The flat file storages of the 60s led to the data warehouses of the 80s to Massively Parallel Processing (MPP) and NoSQL databases, and eventually to data lakes and now the lakehouses. New paradigms continue to be coined but it would be fair to say that most enterprise organizations have settled on some variation of a data lake and lakehouse:
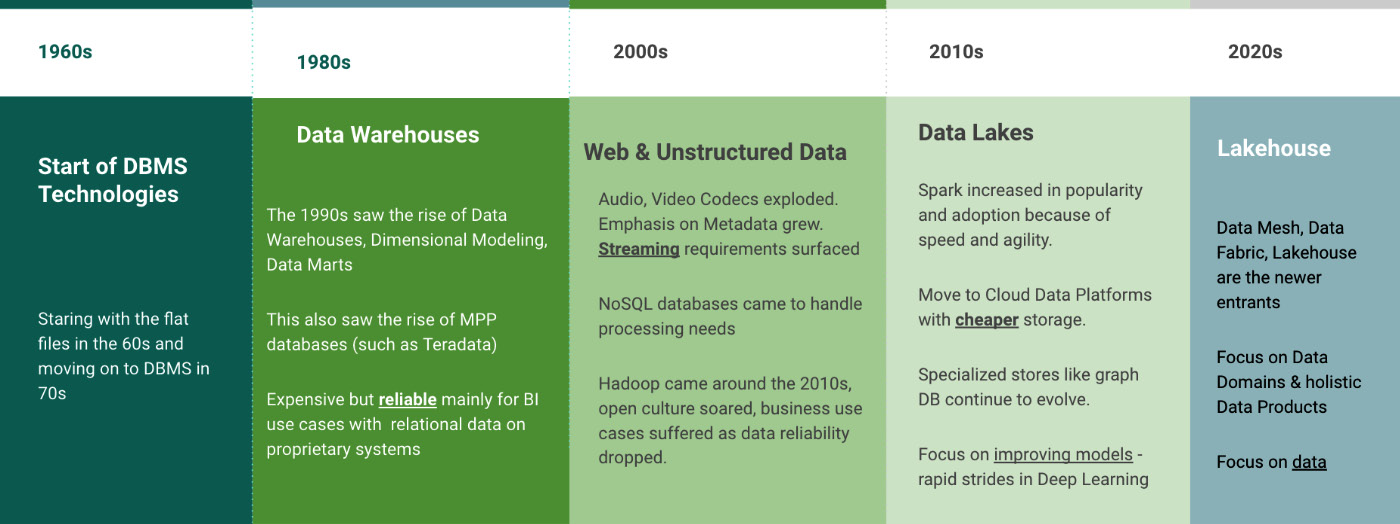
In the last few years, many organizations have modernized their data engineering and analytics platforms by moving away from traditional data warehouses to data lakes. The move to the data lake has undoubtedly given them the flexibility to store and compute any format of data at a large scale. However, these advantages did not come without a few sacrifices along the way. The biggest one is the reliability of data. Like data warehouses, there is no transactional assurance available in a data lake. This need led to the launch of an open source storage layer known as Delta Lake. After its launch, experts came up with the idea of mixing the power of resilient data warehouses with the flexibility of data lakes and they called it a lakehouse.
Traditionally, organizations have been using a data warehouse for their analytical needs. As the business requirements evolved and data scale increased, they started adopting a modern data warehouse architecture which can process massive amounts of data in a relational format and in parallel across multiple compute nodes. At the same time, they started collecting and managing their non-relational big data that was in semi-structured or unstructured format with a data lake. These two disparate yet related systems ran in silos, increasing development time, operational overhead, and overall total cost of ownership. It caused an inconvenience to end users to integrate data if they needed access to the data from both systems to meet their business requirements. Data Lakehouse platform architecture combines the best of both worlds in a single data platform, offering and combining capabilities from both these earlier data platform architectures into a single unified data platform – sometimes also called as medallion architecture. It means, the data lakehouse is the one platform to unify all your data, analytics, and Artificial Intelligence/Machine Learning (AI/ML) workloads.

Most data engineering teams when building data pipelines typically move data from Application Databases to Data Lakes and then move a subset of the data into a Data Warehouse for reporting purposes. But with Lakehouse architecture, we combine Data Lake and Data Warehouse into a Lakehouse, so that your data is moving across just two types of systems. Also Lakehouse can support ingestion of both Streaming and Batch data into the same data structure. This obviates the extra step to consolidate batch and streaming data. This results in a more streamlined Data Pipeline with the fewest hops and faster time to value. So, with a Lakehouse, in most cases, it takes less than 5 minutes to get your data from the point it was generated to the point where it can be reported on in a dashboard.

You now run all scenarios - BI as well as data science, on a single platform, and you don’t have a cloud data warehouse.
Lakehouse helps you simplify data processing and democratize the usage of the data across your organization at the lowest cost possible. This is a game changer for small and big enterprises which are falling behind in the pursuit of leveraging data to gain competitive advantage. So say goodbye to Data warehouses and say hello to Lakehouse and you will never look back as you will be the superhero to all your data users.
To enable a data lakehouse architecture, you need to ensure you leverage one of the open data technologies such as Apache Iceberg or Delta Lake or Apache Hudi, and a compute framework that understands and respects these formats. Cloud providers are continuing to work on toolsets and services that simplify the architecture and operationalization of the data lakehouse. Specifically, an example worth calling out is AWS services that make a data lakehouse implementation easier by leveraging AWS Glue for data integration and orchestration, AWS S3 as the cloud data lake storage, and Amazon Athena to query data from AWS S3 using standard SQL that is familiar to business intelligence users.
Data warehouses have a long history in decision support and business intelligence applications. Since its inception in the late 1980s, data warehouse technology continued to evolve and MPP architectures led to systems that were able to handle larger data sizes. But while warehouses were great for structured data, a lot of modern enterprises have to deal with unstructured data, semi-structured data, and data with high variety, velocity, and volume. Data warehouses are not suited for many of these use cases, and they are certainly not the most cost efficient.
As companies began to collect large amounts of data from many different sources, architects began envisioning a single system to house data for many different analytic products and workloads. About a decade ago companies began building data lakes – repositories for raw data in a variety of formats. While suitable for storing data, data lakes lack some critical features: they do not support transactions, they do not enforce data quality, and their lack of consistency / isolation makes it almost impossible to mix appends and reads, and batch and streaming jobs. For these reasons, many of the promises of the data lakes have not materialized, and in many cases leading to a loss of many of the benefits of data warehouses.
The need for a flexible, high-performance system hasn’t abated. Companies require systems for diverse data applications including SQL analytics, real-time monitoring, data science, and machine learning. Most of the recent advances in AI have been in better models to process unstructured data (text, images, video, audio), but these are precisely the types of data that a data warehouse is not optimized for. A common approach is to use multiple systems – a data lake, several data warehouses, and other specialized systems such as streaming, time-series, graph, and image databases. Having a multitude of systems introduces complexity and more importantly, introduces delay as data professionals invariably need to move or copy data between different systems.
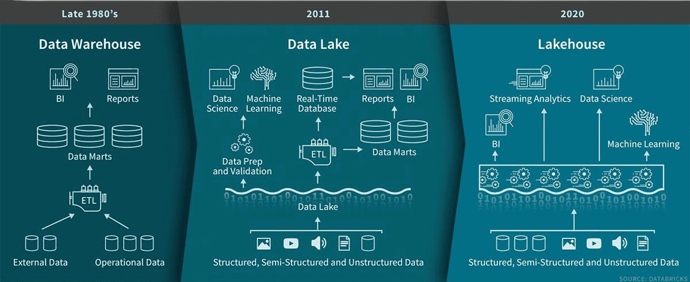
New systems are beginning to emerge that address the limitations of data lakes. A lakehouse is a new, open architecture that combines the best elements of data lakes and data warehouses. Lakehouses are enabled by a new open and standardized system design: implementing similar data structures and data management features to those in a data warehouse, directly on the kind of low cost storage used for data lakes. They are what you would get if you had to redesign data warehouses in the modern world, now that cheap and highly reliable storage (in the form of object stores) are available.
A lakehouse has the following key features:
- Transaction support: In an enterprise lakehouse many data pipelines will often be reading and writing data concurrently. Support for ACID transactions ensures consistency as multiple parties concurrently read or write data, typically using SQL.
- Schema enforcement and governance: The Lakehouse should have a way to support schema enforcement and evolution, supporting DW schema architectures such as star/snowflake-schemas. The system should be able to reason about data integrity, and it should have robust governance and auditing mechanisms.
- BI support: Lakehouses enable using BI tools directly on the source data. This reduces staleness and improves recency, reduces latency, and lowers the cost of having to operationalize two copies of the data in both a data lake and a warehouse.
- Storage is decoupled from compute: In practice this means storage and compute use separate clusters, thus these systems are able to scale to many more concurrent users and larger data sizes. Some modern data warehouses also have this property.
- Openness: The storage formats they use are open and standardized, such as Parquet, and they provide an API so a variety of tools and engines, including machine learning and Python/R libraries, can efficiently access the data directly.
- Support for diverse data types ranging from unstructured to structured data: The lakehouse can be used to store, refine, analyze, and access data types needed for many new data applications, including images, video, audio, semi-structured data, and text.
- Support for diverse workloads: including data science, machine learning, and SQL and analytics. Multiple tools might be needed to support all these workloads but they all rely on the same data repository.
- End-to-end streaming: Real-time reports are the norm in many enterprises. Support for streaming eliminates the need for separate systems dedicated to serving real-time data applications.
These are the key attributes of lakehouses. Enterprise grade systems require additional features. Tools for security and access control are basic requirements. Data governance capabilities including auditing, retention, and lineage have become essential particularly in light of recent privacy regulations. Tools that enable data discovery such as data catalogs and data usage metrics are also needed. With a lakehouse, such enterprise features only need to be implemented, tested, and administered for a single system.
Read the full research paper on the inner workings of the Lakehouse.
What is the right architecture for me?
| Architecture | Total cost of solution | Flexibility of scenarios | Complexity of development | Maturity of ecosystem | Organizational maturity required |
|---|---|---|---|---|---|
| Cloud data warehouse | High - given cloud data warehouses rely on proprietary data formats and offer an end to end solution together, the cost is high | Low - Cloud data warehouses are optimized for BI/SQL based scenarios, there is some support for data science/exploratory scenarios which is restrictive due to format constraints | Low - there is less moving parts and you can get started almost immediately with an end to end solution | High - for SQL/BI scenarios, Low - for other scenarios | Low - the tools and ecosystem are largely well understood and ready to be consumed by organizations of any shape/size. |
| Modern data warehouse | Medium - the data preparation and historical data can be moved to the data lake at lower cost, still need a cloud warehouse which is expensive | Medium - diverse ecosystem of tools nad more exploratory scenarios supported in the data lake, correlating data in the warehouse and data lake needs data copies | Medium - the data engineering team needs to ensure that the data lake design is efficient and scalable, plenty of guidance and considerations available, including this book | Medium - the data preparation and data engineering ecosystem, such as Spark/Hadoop has a higher maturity, tuning for performance and scale needed, High - for consumption via data warehouse | Medium - the data platform team needs to be skilled up to understand the needs of the organization and make the right design choices at the least to support the needs of the organization |
| Data lakehouse | Low - the data lake storage acts as the unified repository with no data movement required, compute engines are largely stateless and can be spun up and down on demand | High - flexibility of running more scenarios with a diverse ecosystem enabling more exploratory analysis such as data science, and ease of sharing of data between BI and data science teams | Medium to High - careful choice of right datasets and the open data format needed to support the lakehouse architecture | Medium to High - while technologies such as Delta Lake, Apache Iceberg, and Apache Hudi are gaining maturity and adoption, today, this architecture requires thoughtful design | Medium to High - the data platform team needs to be skilled up to understand the needs of the organization and the technology choices that are still new |
| Data mesh | Medium - while the distributed design ensures cost is lower, lot of investment required in automation/blueprint/data governance solutions | High - flexibility in supporting different architectures and solutions in the same organization, and no bottlenecks on a central lean organization | High - this relies on an end to end automated solution and an architecture that scales to 10x growth and sharing across architectures/cloud solutions | Low - relatively nascent in guidance and available toolsets | High - data platform team and product/domain teams need to be skilled up in data lakes. |
Hybrid approaches
Depending on your organizational needs, the maturity of your scenarios, and your data platform strategy, you could end up having a hybrid approach to your data lake. As an example, when most of the organization runs on a cloud data warehouse as its central data repository, there is a center of innovation working with a set of handpicked scenarios on a data lake architecture and then gradually expanding to the rest of the company. On another hand, while most of the organizations adopt a data lakehouse architecture, you might find some teams still dependent on legacy infrastructure that would take years to move.
Tools
The Databricks Platform has the architectural features of a lakehouse. Microsoft’s Azure Synapse Analytics service, which integrates with Azure Databricks, enables a similar lakehouse pattern. Other managed services such as BigQuery and Redshift Spectrum have some of the lakehouse features listed above, but they are examples that focus primarily on BI and other SQL applications. Companies who want to build and implement their own systems have access to open source file formats (Delta Lake, Apache Iceberg, Apache Hudi) that are suitable for building a lakehouse.
Merging data lakes and data warehouses into a single system means that data teams can move faster as they are able use data without needing to access multiple systems. The level of SQL support and integration with BI tools among these early lakehouses are generally sufficient for most enterprise data warehouses. Materialized views and stored procedures are available but users may need to employ other mechanisms that aren’t equivalent to those found in traditional data warehouses. The latter is particularly important for “lift and shift scenarios”, which require systems that achieve semantics that are almost identical to those of older, commercial data warehouses.
What about support for other types of data applications? Users of a lakehouse have access to a variety of standard tools (Spark, Python, R, machine learning libraries) for non BI workloads like data science and machine learning. Data exploration and refinement are standard for many analytic and data science applications. Delta Lake is designed to let users incrementally improve the quality of data in their lakehouse until it is ready for consumption.
While distributed file systems can be used for the storage layer, objects stores are more commonly used in lakehouses. Object stores provide low cost, highly available storage, that excel at massively parallel reads – an essential requirement for modern data warehouses.
AWS Data Lake
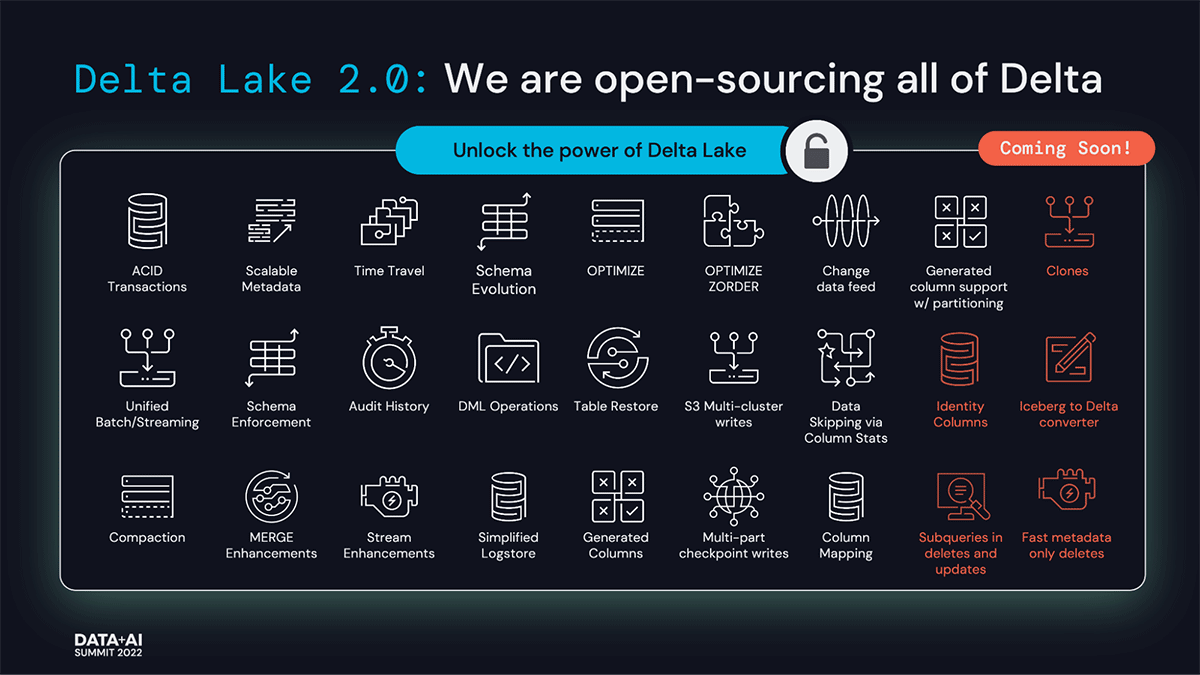
Delta Lake
An open-source storage format that brings ACID transactions to Apache Spark™ and big data workloads.
- Open format: Stored as Parquet format in blob storage.
- ACID Transactions: Ensures data integrity and read consistency with complex, concurrent data pipelines.
- Schema Enforcement and Evolution: Ensures data cleanliness by blocking writes with unexpected.
- Audit History: History of all the operations that happened in the table.
- Time Travel: Query previous versions of the table by time or version number.
- Deletes and upserts: Supports deleting and upserting into tables with programmatic APIs.
- Scalable Metadata management: Able to handle millions of files are scaling the metadata operations with Spark.
- Unified Batch and Streaming Source and Sink: A table in Delta Lake is both a batch table, as well as a streaming source and sink. Streaming data ingest, batch historic backfill, and interactive queries all just work out of the box.
Case studies
- Amazon's migration from On-Premise Oracle database to S3 datalake
- Claimforce's migration from datalake to lakehouse
- How Woot.com built a serverless data lake on AWS
Interview Questions
What is a Data Lakehouse?
In short, a Data Lakehouse is an architecture that enables efficient and secure Artificial Intelligence (AI) and Business Intelligence (BI) directly on vast amounts of data stored in Data Lakes.
Today, the vast majority of enterprise data lands in data lakes, low-cost storage systems that can manage any type of data (structured or unstructured) and have an open interface that any processing tool can run against. These data lakes are where most data transformation and advanced analytics workloads (such as AI) run to take advantage of the full set of data in the organization. Separately, for Business Intelligence (BI) use cases, proprietary data warehouse systems are used on a much smaller subset of the data that is structured. These data warehouses primarily support BI, answering historical analytical questions about the past using SQL (e.g., what was my revenue last quarter), while the data lake stores a much larger amount of data and supports analytics using both SQL and non-SQL interfaces, including predictive analytics and AI (e.g. which of my customers will likely churn, or what coupons to offer at what time to my customers). Historically, to accomplish both AI and BI, you would have to have multiple copies of the data and move it between data lakes and data warehouses.
The Data Lakehouse enables storing all your data once in a data lake and doing AI and BI on that data directly. It has specific capabilities to efficiently enable both AI and BI on all the enterprise’s data at a massive scale. Namely, it has the SQL and performance capabilities (indexing, caching, MPP processing) to make BI work fast on data lakes. It also has direct file access and direct native support for Python, data science, and AI frameworks without ever forcing it through a SQL-based data warehouse. The key technologies used to implement Data Lakehouses are open source, such as Delta Lake, Hudi, and Iceberg. Vendors who focus on Data Lakehouses include, but are not limited to Databricks, AWS, Dremio, and Starburst. Vendors who provide Data Warehouses include, but are not limited to, Teradata, Snowflake, and Oracle.
Recently, Bill Inmon, widely considered the father of data warehousing, published a blog post on the Evolution of the Data Lakehouse explaining the unique ability of the lakehouse to manage data in an open environment while combining the data science focus of the data lake with the end-user analytics of the data warehouse.
What is a Data Lake?
A data lake is a low-cost, open, durable storage system for any data type - tabular data, text, images, audio, video, JSON, and CSV. In the cloud, every major cloud provider leverages and promotes a data lake, e.g. AWS S3, Azure Data Lake Storage (ADLS), Google Cloud Storage (GCS). As a result, the vast majority of the data of most organizations is stored in cloud data lakes. Over time, most organizations store their data in an open standardized format, typically either Apache Parquet format or ORC format. As a result, a large ecosystem of tools and applications can directly work with these open data formats. This approach of storing data in open formats, at a very low cost has enabled organizations to amass large quantities of data in data lakes while avoiding vendor lock-in. At the same time, data lakes have suffered from three main problems - security, quality, and performance despite these advantages. Since all the data is stored and managed as files, it does not provide fine-grained access control on the contents of files, but only coarse-grained access governing who can access what files or directories. The query performance is poor because the formats are not optimized for fast access, and listing files is computationally expensive. In short, organizations end up moving data into other systems to make use of the data, unless the applications can tolerate noise (i.e. machine learning). Finally, quality is a challenge because it’s hard to prevent data corruption and manage schema changes as more and more data gets ingested to the data lake. Similarly, it is challenging to ensure atomic operations when writing a group of files, and no mechanism to roll back changes. As a result, many argue that most data lakes end up becoming data “swamps”. . Consequently, most organizations move subsets of this data into Data Warehouses, which do not have these three problems, but suffer from other problems.
What is a Data Warehouse?
Data warehouses are proprietary systems that are built to store and manage only structured or semi-structured (primarily JSON format) data for SQL-based analytics and business intelligence. The most valuable business data is curated and uploaded to data warehouses, which are optimized for high performance, concurrency, and reliability but at a much higher cost, as any data processing will have to be at more expensive SQL rates rather than cheap data lake access rates. Historically, data warehouses were capacity constrained and could not support simultaneous ETL and BI queries; much less real-time streaming. Since data warehouses were primarily built for structured data, they do not support unstructured data such as images, sensor data, documents, videos, etc. They have limited support for machine learning and cannot directly support popular open source libraries and tools (TensorFlow, PyTorch, and other Python-based libraries) natively. As a result, most organizations end up keeping these data sets in a data lake, moving subsets into a data warehouse for fast concurrent BI and SQL use cases
How is a Data Lakehouse different from a Data Warehouse?
The lakehouse builds on top of existing data lakes, which often contain more than 90% of the data in the enterprise. While most data warehouses support “external table” functionality to access that data, they have severe functionality limitations (e.g., only supporting read operations) and performance limitations when doing so. Lakehouse instead adds traditional data warehousing capabilities to existing data lakes, including ACID transactions, fine-grained data security, low-cost updates and deletes, first-class SQL support, optimized performance for SQL queries, and BI style reporting. By building on top of a data lake, the Lakehouse stores and manages all existing data in a data lake, including all varieties of data, such as text, audio and video, in addition to structured data in tables. Lakehouse also natively supports data science and machine learning use cases by providing direct access to data using open APIs and supporting various ML and Python/R libraries, such as PyTorch, Tensorflow or XGBoost, unlike data warehouses. Thus, Lakehouse provides a single system to manage all of an enterprise’s data while supporting the range of analytics from BI and AI.
On the other hand, data warehouses are proprietary data systems that are purpose-built for SQL-based analytics on structured data, and certain types of semi-structured data. Data warehouses have limited support for machine learning and cannot support running popular open source tools natively without first exporting the data (either through ODBC/JDBC or to a data lake). Today, no data warehouse system has native support for all the existing audio, image, and video data that is already stored in data lakes.
How is the Data Lakehouse different from a Data Lake?
The most common complaint about data lakes is that they can become data swamps. Anybody can dump any data into a data lake; there is no structure or governance to the data in the lake. Performance is poor, as data is not organized with performance in mind, resulting in limited analytics on data lakes. As a result, most organizations use data lakes as a landing zone for most of their data due to the underlying low-cost object storage data lakes use and then move the data to different downstream systems such as data warehouses to extract value.
Lakehouse tackles the fundamental issues that make data swamps out of data lakes. It adds ACID transactions to ensure consistency as multiple parties concurrently read or write data. It supports DW schema architectures like star/snowflake-schemas and provides robust governance and auditing mechanisms directly on the data lake. It also leverages various performance optimization techniques, such as caching, multi-dimensional clustering, and data skipping, using file statistics and data compaction to right-size the files enabling fast analytics. And it adds fine-grained security and auditing capabilities for data governance. By adding data management and performance optimizations to the open data lake, lakehouse can natively support BI and ML applications.
How easy is it for data analysts to use a Data Lakehouse?
Data lakehouse systems implement the same SQL interface as traditional data warehouses, so analysts can connect to them in existing BI and SQL tools without changing their workflows. For example, leading BI products such as Tableau, PowerBI, Qlik, and Looker can all connect to data lakehouse systems, data engineering tools like Fivetran and dbt can run against them, and analysts can export data into desktop tools such as Microsoft Excel. Lakehouse’s support for ANSI SQL, fine-grained access control, and ACID transactions enables administrators to manage them the same way as data warehouse systems but cover all the data in their organization in one system.
One important advantage of Lakehouse systems in simplicity is that they manage all the data in the organization, so data analysts can be granted access to work with raw and historical data as it arrives instead of only the subset of data loaded into a data warehouse system. An analyst can therefore easily ask questions that span multiple historical datasets or establish a new pipeline for working with a new dataset without blocking on a database administrator or data engineer to load the appropriate data. Built-in support for AI also makes it easy for analysts to run AI models built by a machine learning team on any data.
How do Data Lakehouse systems compare in performance and cost to data warehouses?
Data Lakehouse systems are built around separate, elastically scaling compute and storage to minimize their cost of operation and maximize performance. Recent systems provide comparable or even better performance per dollar to traditional data warehouses for SQL workloads, using the same optimization techniques inside their engines (e.g., query compilation and storage layout optimizations). In addition, Lakehouse systems often take advantage of cloud provider cost-saving features such as spot instance pricing (which requires the system to tolerate losing worker nodes mid-query) and reduced prices for infrequently accessed storage, which traditional data warehouse engines have usually not been designed to support.
What data governance functionality do Data Lakehouse systems support?
By adding a management interface on top of data lake storage, Lakehouse systems provide a uniform way to manage access control, data quality, and compliance across all of an organization’s data using standard interfaces similar to those in data warehouses. Modern Lakehouse systems support fine-grained (row, column, and view level) access control via SQL, query auditing, attribute-based access control, data versioning, and data quality constraints and monitoring. These features are generally provided using standard interfaces familiar to database administrators (for example, SQL GRANT commands) to allow existing personnel to manage all the data in an organization in a uniform way. Centralizing all the data in a Lakehouse system with a single management interface also reduces the administrative burden and potential for error that comes with managing multiple separate systems.
Does the Data Lakehouse have to be centralized or can it be decentralized into a Data Mesh?
No, organizations do not need to centralize all their data in one Lakehouse. Many organizations using the Lakehouse architecture take a decentralized approach to store and process data but take a centralized approach to security, governance, and discovery. Depending on organizational structure and business needs, we see a few common approaches:
- Each business unit builds its own Lakehouse to capture its business' complete view – from product development to customer acquisition to customer service.
- Each functional area, such as product manufacturing, supply chain, sales, and marketing, could build its own Lakehouse to optimize operations within its business area.
- Some organizations also spin up a new Lakehouse to tackle new cross-functional strategic initiatives such as customer 360 or unexpected crises like the COVID pandemic to drive fast, decisive action.
The unified nature of the Lakehouse architecture enables data architects to build simpler data architectures that align with the business needs without complex orchestration of data movement across siloed data stacks for BI and ML. Furthermore, the openness of the Lakehouse architecture enables organizations to leverage the growing ecosystem of open technologies without fear of lock-in to addressing the unique needs of the different business units or functional areas. Because Lakehouse systems are usually built on separated, scalable cloud storage, it is also simple and efficient to let multiple teams access each lakehouse. Recently, Delta Sharing proposed an open and standard mechanism for data sharing across Lakehouses with support from many different vendors.
How does the Data Mesh relate to the Data Lakehouse?
Zhamak Dehghani has outlined four fundamental organizational principles that embody any data mesh implementation. The Data Lakehouse architecture can be used in implementing these organizational principles:
- Domain-oriented decentralized data ownership and architecture: As discussed in the previous section, the lakehouse architecture takes a decentralized approach to data ownership. Organizations can create many different lakehouses to serve the individual needs of the business groups. Based on their needs, they can store and manage various data – images, video, text, structured tabular data, and related data assets such as machine learning models and associated code to reproduce transformations and insights.
- Data as a product: The lakehouse architecture helps organizations manage data as a product by providing different data team members in domain-specific teams complete control over the data lifecycle. Data team comprising of a data owner, data engineers, analysts, and data scientists can manage data (structured, semi-structured, and unstructured with proper lineage and security controls), code (ETL, data science notebooks, ML training, and deployment), and supporting infrastructure (storage, compute, cluster policies, and various analytics and ML engines). Lakehouse platform features such as ACID transactions, data versioning, and zero-copy cloning make it easy for these teams to publish and maintain their data as a product.
- Self-serve data infrastructure as a platform: The lakehouse architecture provides an end-to-end data platform for data management, data engineering, analytics, data science, and machine learning with integrations to a broad ecosystem of tools. Adding data management on top of existing data lakes simplifies data access and sharing – anyone can request access, the requester pays for cheap blob storage and gets immediate secure access. In addition, using open data formats and enabling direct file access, data teams can use best-of-breed analytics and ML frameworks on the data.
- Federated computational governance: The governance in the lakehouse architecture is implemented by a centralized catalog with fine-grained access controls (row/column level), enabling easy discovery of data and other artifacts like code and ML models. Organizations can assign different administrators to different parts of the catalog to decentralize control and management of data assets. This hybrid approach of a centralized catalog with federated control preserves the independence and agility of the local domain-specific teams while ensuring data asset reuse across these teams and enforcing a common security and governance model globally.
More Resources
- Data Lake / Lakehouse Guide: Powered by Data Lake Table Formats (Delta Lake, Iceberg, Hudi)
- https://martinfowler.com/bliki/DataLake.html
- Top Delta Lake Interview Questions
- https://www.databricks.com/blog/2021/08/30/frequently-asked-questions-about-the-data-lakehouse.html
- http://www.igfasouza.com/blog/what-is-data-lake
- https://40uu5c99f3a2ja7s7miveqgqu-wpengine.netdna-ssl.com/wp-content/uploads/2017/02/Understanding-data-lakes-EMC.pdf