dbt
dbt (data build tool) is an open source Python package that enables data analysts and engineers to transform their data using the same practices that software engineers use to build applications. dbt allows you to build your data transformation pipeline using SQL queries.
dbt fits nicely into the modern BI stack, coupling with products like Stitch, Fivetran, Redshift, Snowflake, BigQuery, Looker, and Mode. Here’s how the pieces fit together:
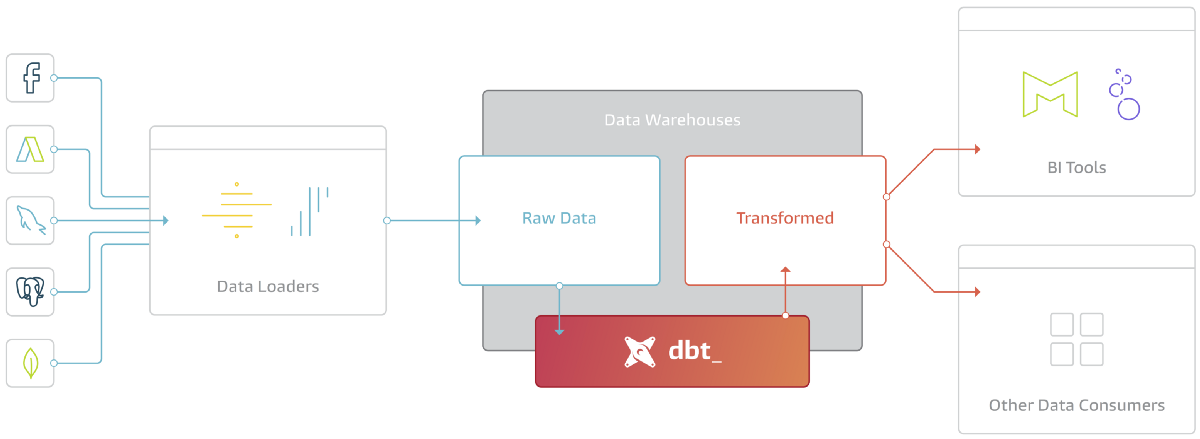
dbt is the T in ELT. It doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse. This “transform after load” architecture is becoming known as ELT (extract, load, transform).
ELT has become commonplace because of the power of modern analytic databases. Data warehouses like Redshift, Snowflake, and BigQuery are extremely performant and very scalable such that at this point most data transformation use cases can be much more effectively handled in-database rather than in some external processing layer. Add to this the separation of compute and storage and there are decreasingly few reasons to want to execute your data transformation jobs elsewhere.
dbt is a tool to help you write and execute the data transformation jobs that run inside your warehouse. dbt’s only function is to take code, compile it to SQL, and then run against your database.
Want to deep-dive?
https://www.youtube.com/playlist?list=PLy4OcwImJzBLJzLYxpxaPUmCWp8j1esvT
Data modeling techniques for more modularity
https://www.getdbt.com/analytics-engineering/modular-data-modeling-technique/
Commands
init:
dbt init ${PROJECT_NAME}
debug:
dbt debug
run:
dbt run
dbt run --profiles-dir path/to/directory
export DBT_PROFILES_DIR=path/to/directory
test:
dbt test -m model1 [model2]
seed:
dbt seed
dbt-core
dbt-databricks
dbt-postgres
dbt-snowflake
postgres:
outputs:
dev:
type: postgres
threads: 1
host: <host>
port: 5432
user: postgres
pass: <pass>
dbname: postgres
schema: public
prod:
type: postgres
threads: 1
host: <host>
port: 5432
user: postgres
pass: <pass>
dbname: postgres
schema: public
target: dev
databricks:
outputs:
dev:
host: {HOST}
http_path: {HTTP_PATH}
schema: default
threads: 1
token: {TOKEN}
type: databricks
target: dev

More Resources
- Getting Started with dbt
- Transforming data with dbt
- Transform your data with dbt and Serverless architecture
- How JetBlue is eliminating the data engineering bottlenecks with dbt
- dbt development at Vimeo
- Best practices for data modeling with SQL and dbt
- https://www.getdbt.com/analytics-engineering/start-here
- https://www.getdbt.com/blog/what-exactly-is-dbt/
- Four Reasons that make DBT a great time saver for Data Engineers
- https://courses.getdbt.com/courses/fundamentals