Amazon Kinesis
Watch these videos:
Kinesis Data Firehose
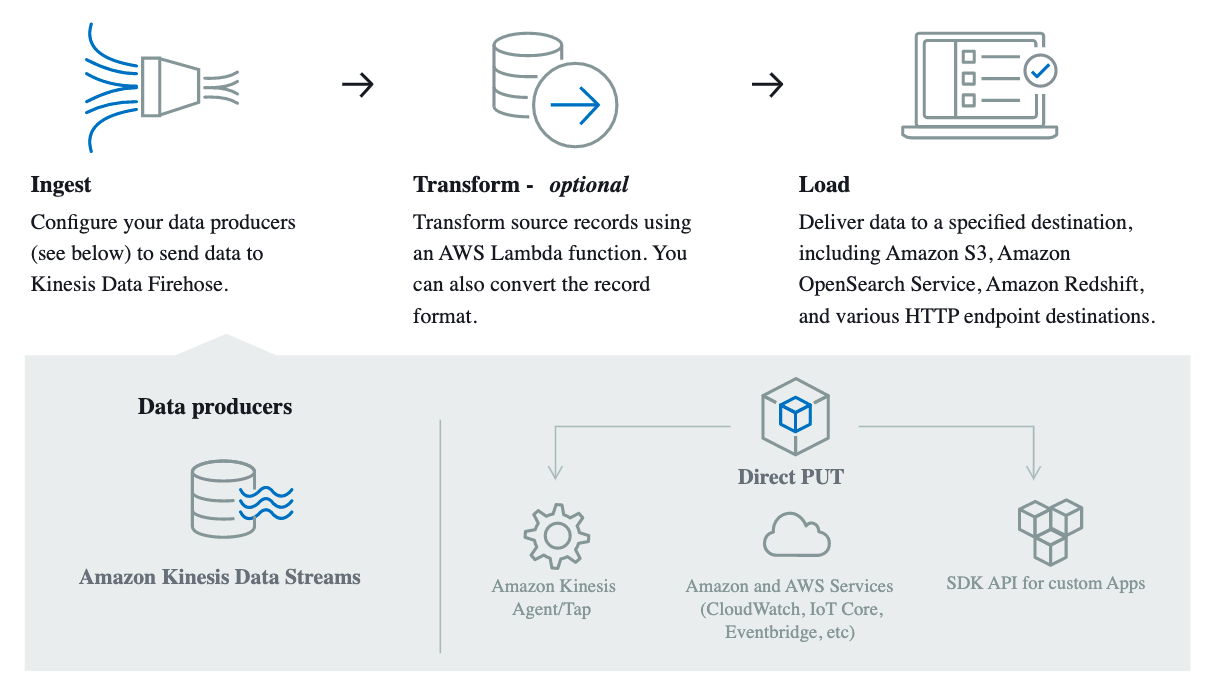
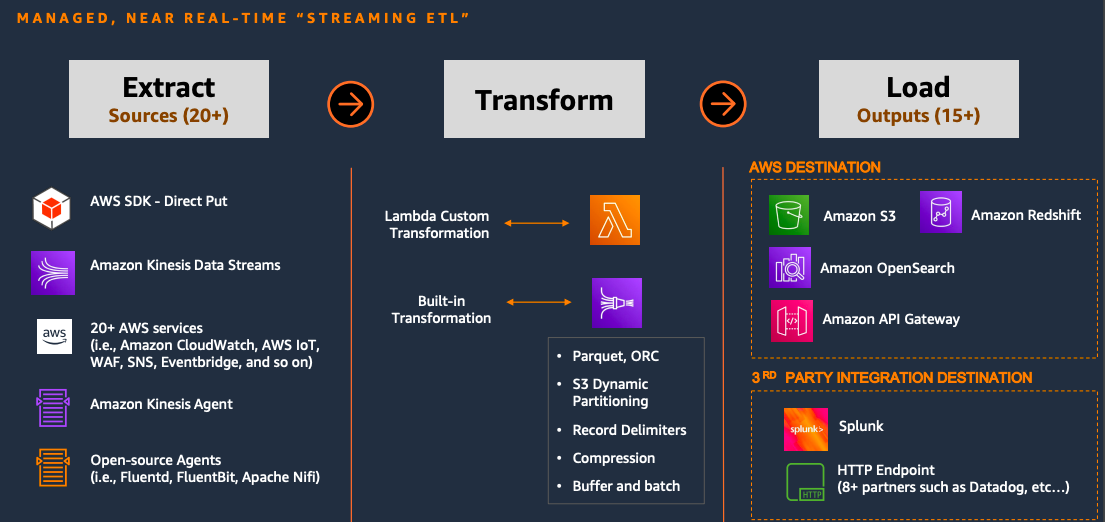
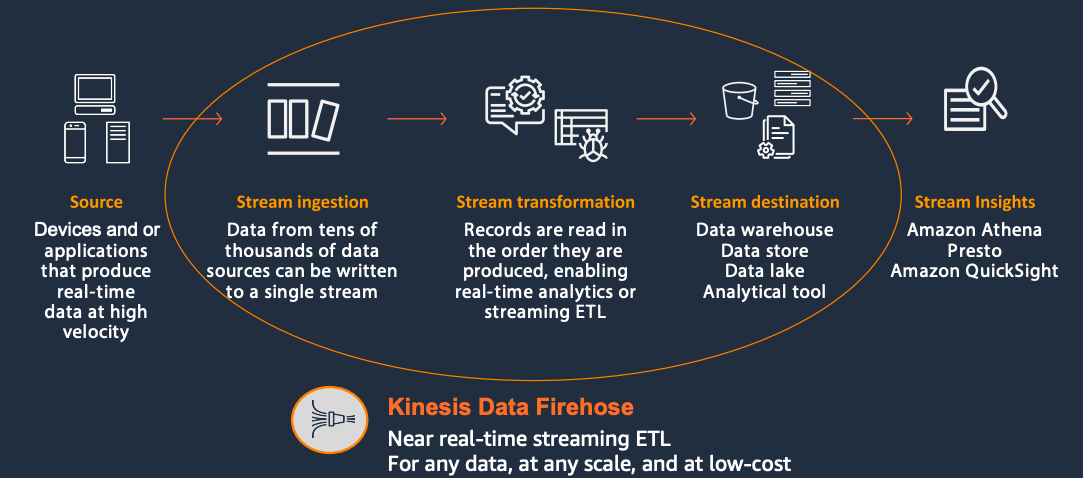
Why Kinesis Data Firehose ?
- Ease of Use: With just a few clicks, create your delivery stream. Connect to your destination in under a minute
- No Code Required: Handles data delivery failures, Built-in transformations, 30+ sources and destinations
- Serverless with Elastic Scale: Firehose automatically provisions, manages and scales resources with no on-going administration required
- Low Cost: Data can be prepared and delivered at pennies per delivered GB with any scale
In-transit Dynamic Partitioning
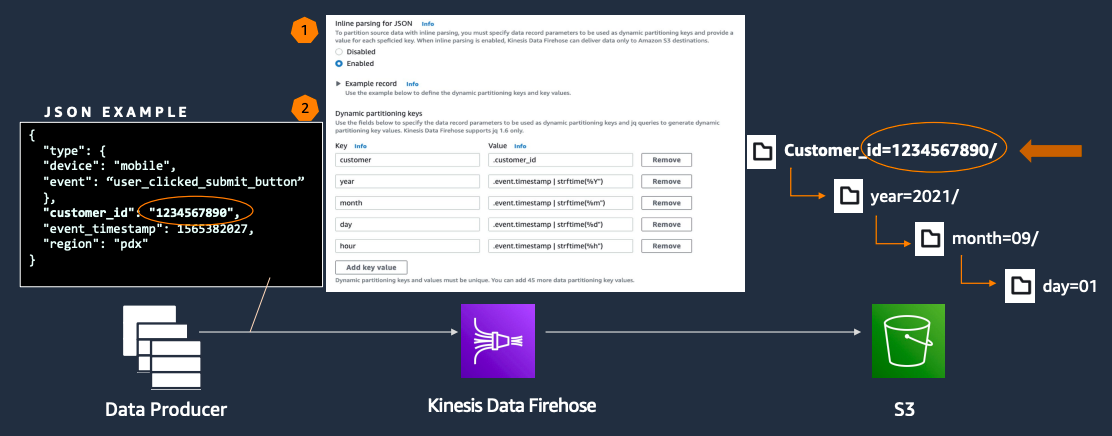
Traditionally, customers use Kinesis Data Firehose delivery streams to capture and load their data into Amazon S3 based data lakes for analytics. Partitioning the data while storing on Amazon Simple Storage Service(S3) is a best practice for optimizing performance and reducing the cost of analytics queries because partitions minimize the amount of data scanned. By default, Kinesis Firehose creates a static Universal Coordinated Time (UTC) based folder structure in the format of YYYY/MM/dd/HH. It is then appended it to the provided prefix before writing objects to Amazon S3.
With Dynamic Partitioning, Kinesis Data Firehose will continuously group data in-transit by dynamically or statically defined data keys, and deliver to individual Amazon S3 prefixes by key. This will reduce time-to-insight by minutes or hours, reducing costs and simplifying architectures. This feature combined with Kinesis Data Firehose's Apache Parquet and Apache ORC format conversion feature makes Kinesis Data Firehose an ideal option for capturing, preparing, and loading data that is ready for analytic queries and data processing. Review Kinesis Data Firehose documentation for additional details on Kinesis Data Firehose dynamic partitioning feature.
Use Cases

Best Practices
Consider the following best practices when deploying Kinesis Firehose:
- Record Size Limit: The maximum size of a record sent to Kinesis Data Firehose is 1,000 KB. If your message size is greater than this value, compressing the message before it is sent to Kinesis Data Firehose is the best approach.
- Buffering hints: Buffering hint options are treated as hints. As a result, Kinesis Data Firehose might choose to use different values to optimize the buffering.
- Permissions: Kinesis Data Firehose uses IAM roles for all the permissions that the delivery stream needs. You can choose to create a new role where required permissions are assigned automatically, or choose an existing role created for Kinesis Data Firehose. If you are creating a new role, ensure that you are granting only the permissions that are required to perform a task.
- Encryption: Data at rest and data in transit can be encrypted in Kinesis Data Firehose. Refer to the Kinesis Firehose Documentation .
- Tags: You can add tags to organize your AWS resources, track costs, and control access.
- Costs: Amazon Kinesis Data Firehose uses simple pay as you go pricing. There is neither upfront cost nor minimum fees and you only pay for the resources you use. Amazon Kinesis Data Firehose pricing is based on the data volume (GB) ingested by Firehose, with each record rounded up to the nearest 5KB. The 5KB roundup is calculated at the record level rather than the API operation level. For example, if your PutRecordBatch call contains two 1KB records, the data volume from that call is metered as 10KB. (2 times 5KB per record).