Big Data Architectures
Lambda architecture
Lambda architecture comprises Batch Layer, Speed Layer (also known as Stream layer), and Serving Layer.
The batch layer operates on the complete data and thus allows the system to produce the most accurate results. However, the results come at the cost of high latency due to high computation time. The batch layer stores the raw data as it arrives and computes the batch views for consumption. Naturally, batch processes will occur at some interval and will be long-lived. The scope of data is anywhere from hours to years.
The speed layer generates results in a low-latency, near real-time fashion. The speed layer is used to compute the real-time views to complement the batch views. The speed layer receives the arriving data and performs incremental updates to the batch layer results. Thanks to the incremental algorithms implemented at the speed layer, the computation cost is significantly reduced.
The batch views may be processed with more complex or expensive rules and may have better data quality and less skew, while the real-time views give you up-to-the-moment access to the latest possible data.
Finally, the serving layer enables various queries of the results sent from the batch and speed layers. The outputs from the batch layer in the form of batch views and the speed layer in the form of near-real-time views are forwarded to the serving layer, which uses this data to cater to the pending queries on an ad-hoc basis.
Implementation Example

Pros
- It is a good balance of speed, reliability, and scalability. The batch layer of Lambda architecture manages historical data with the fault-tolerant, distributed storage, ensuring a low possibility of errors even if the system crashes.
- Access to both real-time and offline results in covering many data analysis scenarios very well.
- Having access to a complete data set in a batch window may yield specific optimizations that make Lambda better performing and perhaps even simpler to implement.
Cons
- Although the offline layer and the real-time stream face different scenarios, their internal processing logic is the same, so there are many duplicate modules and coding overhead.
- Reprocesses every batch cycle, which is not beneficial in specific scenarios.
- A data set modeled with Lambda architecture is difficult to migrate or reorganize.
Use Cases
- User queries are required to be served on an ad-hoc basis using immutable data storage.
- Quick responses are required, and the system should handle various updates in new data streams.
- None of the stored records shall be erased, and it should allow the addition of updates and new data to the database.
Kappa architecture
The Kappa architecture solves the redundant part of the Lambda architecture. It is designed with the idea of replaying data. Kappa architecture avoids maintaining two different code bases for the batch and speed layers. The key idea is to handle real-time data processing, and continuous data reprocessing using a single stream processing engine and avoid a multi-layered Lambda architecture while meeting the standard quality of service.
Implementation Example
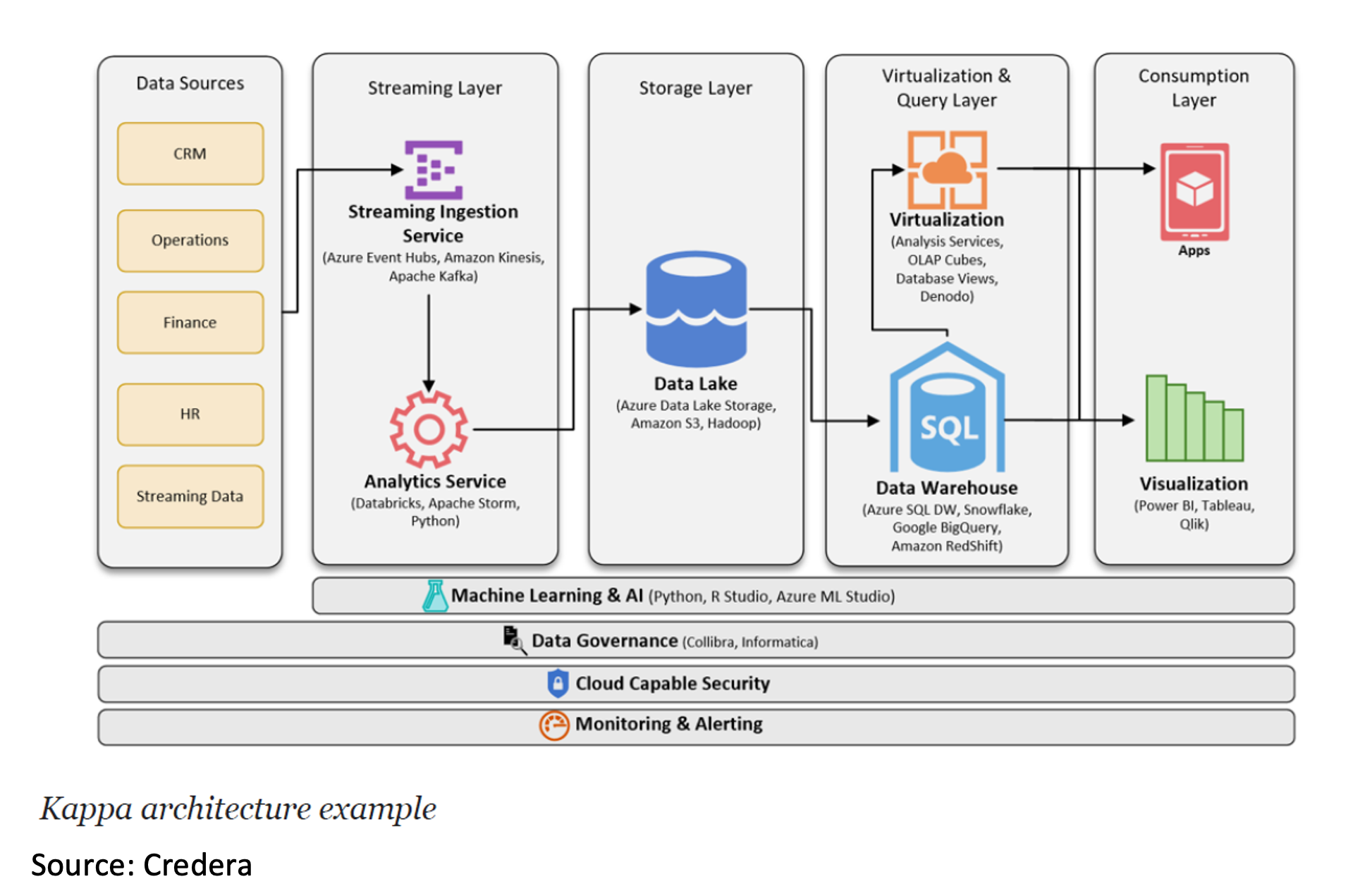
Pros
- Applications can read and write directly to Kafka (or other message queue) as developed. For existing event sources, listeners are used to stream writes directly from database logs (or datastore equivalents), eliminating the need for batch processing during ingress, resulting in fewer resources.
- Treating every data point in your organization as a streaming event also provides you the ability to 'time travel' to any point and see the state of all data in your organization.
- Queries only need to look in a single serving location instead of going against batch and speed views.
Cons
- The complication of this architecture mainly revolves around having to process this data in a stream, such as handling duplicate events, cross-referencing events, or maintaining order - operations that are generally easier to do in batch processing.
- Although the Kappa architecture looks concise, it isn't easy to implement, especially for the data replay.
- For Lambda, catalog services can auto-discover and document file and database systems. Kafka doesn't align with this tooling, so supporting scaling to enterprise-sized environments strongly infers implementing confluent enterprise with a schema registry that attempts to play the role of a catalog service.
Use Cases
- When the algorithms applied to the real-time data and the historical data are identical, it is very beneficial to use the same code base to process historical and real-time data and, therefore, implement the use-case using the Kappa architecture.
- Kappa architecture can be used to develop data systems that are online learners and therefore don't need the batch layer.
- The order of the events and queries is not predetermined. Stream processing platforms can interact with the database at any time.
Conclusion
Kappa is not a replacement for Lambda as some use-cases deployed using the Lambda architecture cannot be migrated.
When you seek an architecture that is more reliable in updating the data lake as well as efficient in training the machine learning models to predict upcoming events robustly, then use the Lambda architecture as it reaps the benefits of both the batch layer and speed layer to ensure few errors and speed.
On the other hand, when you want to deploy big data architecture using less expensive hardware and require it to deal effectively with unique events occurring continuously, then select the Kappa architecture for your real-time data processing needs.
Check out this whitepaper and related webinar to deep dive into this topic.