Delta Lake Deep-dive
Setup
db = "deltadb"
spark.sql(f"CREATE DATABASE IF NOT EXISTS {db}")
spark.sql(f"USE {db}")
spark.sql("SET spark.databricks.delta.formatCheck.enabled = false")
spark.sql("SET spark.databricks.delta.properties.defaults.autoOptimize.optimizeWrite = true")
import random
from datetime import datetime
from pyspark.sql.functions import *
from pyspark.sql.types import *
def my_checkpoint_dir():
return "/tmp/delta_demo/chkpt/%s" % str(random.randint(0, 10000))
# User-defined function to generate random state
@udf(returnType=StringType())
def random_state():
return str(random.choice(["CA", "TX", "NY", "WA"]))
# Function to start a streaming query with a stream of randomly generated load data and append to the parquet table
def generate_and_append_data_stream(table_format, table_name, schema_ok=False, type="batch"):
stream_data = (spark.readStream.format("rate").option("rowsPerSecond", 500).load()
.withColumn("loan_id", 10000 + col("value"))
.withColumn("funded_amnt", (rand() * 5000 + 5000).cast("integer"))
.withColumn("paid_amnt", col("funded_amnt") - (rand() * 2000))
.withColumn("addr_state", random_state())
.withColumn("type", lit(type)))
if schema_ok:
stream_data = stream_data.select("loan_id", "funded_amnt", "paid_amnt", "addr_state", "type", "timestamp")
query = (stream_data.writeStream
.format(table_format)
.option("checkpointLocation", my_checkpoint_dir())
.trigger(processingTime = "5 seconds")
.table(table_name))
return query
# Function to stop all streaming queries
def stop_all_streams():
print("Stopping all streams")
for s in spark.streams.active:
try:
s.stop()
except:
pass
print("Stopped all streams")
dbutils.fs.rm("/tmp/delta_demo/chkpt/", True)
def cleanup_paths_and_tables():
dbutils.fs.rm("/tmp/delta_demo/", True)
dbutils.fs.rm("file:/dbfs/tmp/delta_demo/loans_parquet/", True)
for table in ["deltadb.loans_parquet", "deltadb.loans_delta", "deltadb.loans_delta2"]:
spark.sql(f"DROP TABLE IF EXISTS {table}")
cleanup_paths_and_tables()
Data Ingestion
The data used is a modified version of the public data from Lending Club. It includes all funded loans from 2012 to 2017. Each loan includes applicant information provided by the applicant as well as the current loan status (Current, Late, Fully Paid, etc.) and latest payment information. For a full view of the data please view the data dictionary available here.
%sh mkdir -p /dbfs/tmp/delta_demo/loans_parquet/; wget -O /dbfs/tmp/delta_demo/loans_parquet/loans.parquet https://pages.databricks.com/rs/094-YMS-629/images/SAISEU19-loan-risks.snappy.parquet
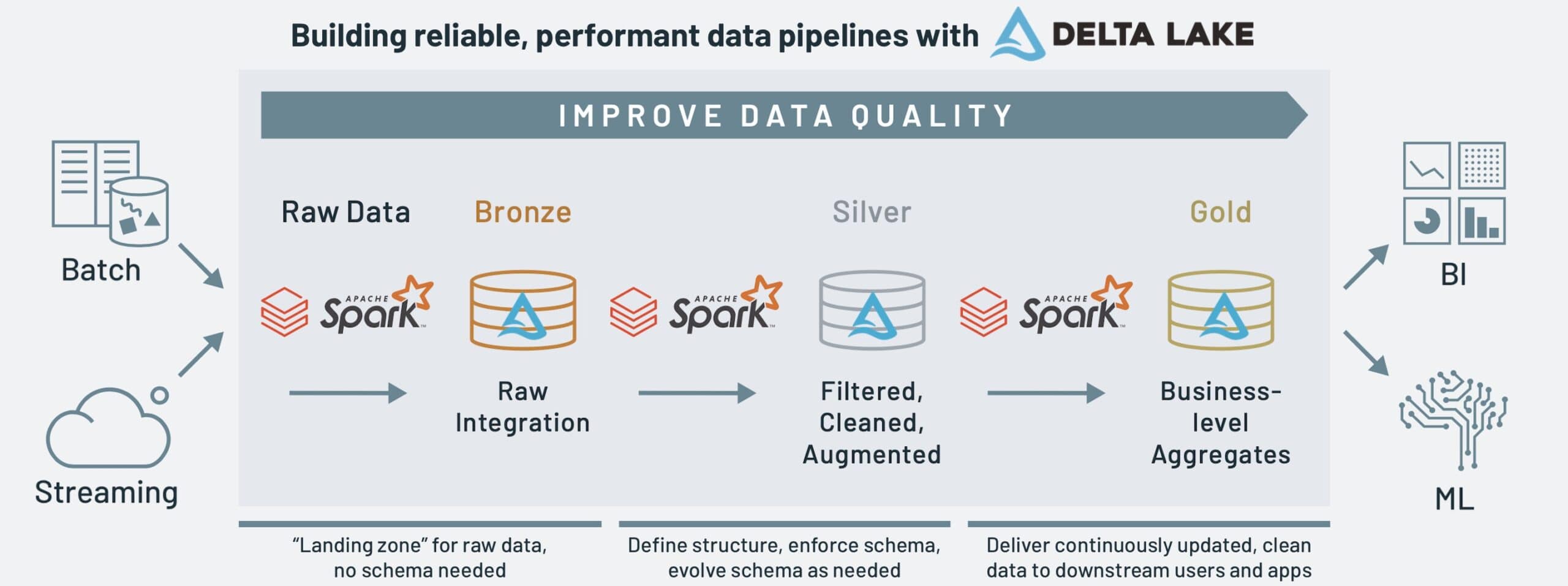
What is Delta Lake?
An open-source storage layer for data lakes that brings ACID transactions to Apache Spark™ and big data workloads.
- ACID Transactions: Ensures data integrity and read consistency with complex, concurrent data pipelines.
- Unified Batch and Streaming Source and Sink: A table in Delta Lake is both a batch table, as well as a streaming source and sink. Streaming data ingest, batch historic backfill, and interactive queries all just work out of the box.
- Schema Enforcement and Evolution: Ensures data cleanliness by blocking writes with unexpected.
- Time Travel: Query previous versions of the table by time or version number.
- Deletes and upserts: Supports deleting and upserting into tables with programmatic APIs.
- Open Format: Stored as Parquet format in blob storage.
- Audit History: History of all the operations that happened in the table.
- Scalable Metadata management: Able to handle millions of files are scaling the metadata operations with Spark.
Conversion to Delta
Delta Lake is 100% compatible with Apache Spark™, which makes it easy to get started with if you already use Spark for your big data workflows. Delta Lake features APIs for SQL, Python, and Scala, so that you can use it in whatever language you feel most comfortable in.
In Python: Read your data into a Spark DataFrame, then write it out in Delta Lake format directly, with no upfront schema definition needed.
parquet_path = "file:/dbfs/tmp/delta_demo/loans_parquet/"
df = (spark.read.format("parquet").load(parquet_path)
.withColumn("type", lit("batch"))
.withColumn("timestamp", current_timestamp()))
df.write.format("delta").mode("overwrite").saveAsTable("loans_delta")
SQL: Use CREATE TABLE statement with SQL (no upfront schema definition needed)
%sql
CREATE TABLE loans_delta2
USING delta
AS SELECT * FROM parquet.`/tmp/delta_demo/loans_parquet`
SQL: Use CONVERT TO DELTA to convert Parquet files to Delta Lake format in place
%sql CONVERT TO DELTA parquet.`/tmp/delta_demo/loans_parquet`
View the data in the Delta Lake table
How many records are there, and what does the data look like?
spark.sql("select count(*) from loans_delta").show()
spark.sql("select * from loans_delta").show(3)
Unified batch + streaming data processing with multiple concurrent readers and writers
Write 2 different data streams into our Delta Lake table at the same time.
# Set up 2 streaming writes to our table
stream_query_A = generate_and_append_data_stream(table_format="delta", table_name="loans_delta", schema_ok=True, type='stream A')
stream_query_B = generate_and_append_data_stream(table_format="delta", table_name="loans_delta", schema_ok=True, type='stream B')
# Create 2 continuous streaming readers of our Delta Lake table to illustrate streaming progress
# Streaming read #1
display(spark.readStream.format("delta").table("loans_delta").groupBy("type").count().orderBy("type"))
# Streaming read #2
display(spark.readStream.format("delta").table("loans_delta").groupBy("type", window("timestamp", "10 seconds")).count().orderBy("window"))
Add a batch query, just for good measure
%sql
SELECT addr_state, COUNT(*)
FROM loans_delta
GROUP BY addr_state
dbutils.notebook.exit("stop")
stop_all_streams()
ACID Transactions
%sql DESCRIBE HISTORY loans_delta
Use Schema Enforcement to protect data quality
To show you how schema enforcement works, let's create a new table that has an extra column -- credit_score -- that doesn't match our existing Delta Lake table schema.
Write DataFrame with extra column, credit_score, to Delta Lake table
# Generate `new_data` with additional column
new_column = [StructField("credit_score", IntegerType(), True)]
new_schema = StructType(spark.table("loans_delta").schema.fields + new_column)
data = [(99997, 10000, 1338.55, "CA", "batch", datetime.now(), 649),
(99998, 20000, 1442.55, "NY", "batch", datetime.now(), 702)]
new_data = spark.createDataFrame(data, new_schema)
new_data.printSchema()
# Uncommenting this cell will lead to an error because the schemas don't match.
# Attempt to write data with new column to Delta Lake table
new_data.write.format("delta").mode("append").saveAsTable("loans_delta")
Schema enforcement helps keep our tables clean and tidy so that we can trust the data we have stored in Delta Lake. The writes above were blocked because the schema of the new data did not match the schema of table (see the exception details). See more information about how it works here.
Use Schema Evolution to add new columns to schema
If we want to update our Delta Lake table to match this data source's schema, we can do so using schema evolution. Simply add the following to the Spark write command: .option("mergeSchema", "true")
new_data.write.format("delta").mode("append").option("mergeSchema", "true").saveAsTable("loans_delta")
%sql SELECT * FROM loans_delta WHERE loan_id IN (99997, 99998)