Data Pipeline with Databricks PySpark and Superset
Put on your data engineer hat! In this project, you’ll build a modern, cloud-based, three-layer data Lakehouse. First, you’ll set up your workspace on the Databricks platform, leveraging important Databricks features, before pushing the data into the first two layers of the data lake. Next, using Apache Spark, you’ll build the third layer, used to serve insights to different end-users. Then, you’ll use Delta Lake to turn your existing data lake into a Lakehouse. Finally, you’ll deliver an infrastructure that allows your end-users to perform specific queries, using Apache Superset, and build dashboards on top of the existing data. When you’re done with the projects in this series, you’ll have a complete big data pipeline for a cloud-based data lake—and you’ll understand why the three-layer architecture is so popular.
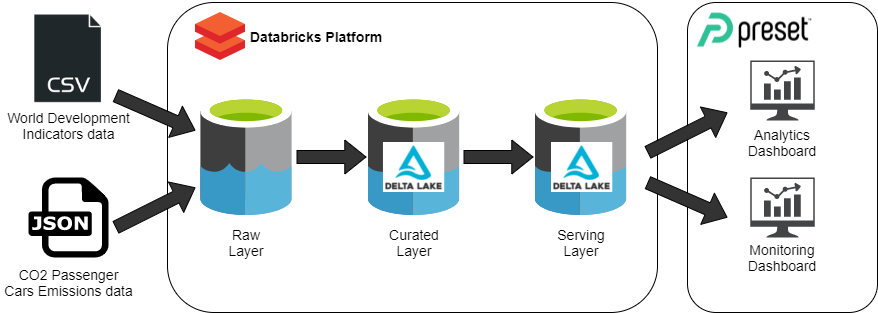
You’ll use your data engineering skills to offer your company’s analytics team the necessary tools to analyze external data provided by the World Bank and monitor the change in CO2 emissions from cars sold within the EU. To do so, you’ll first retrieve different datasets from external sources, ingest them into your company’s lakehouse (which you as the data engineer will need to build), and then perform data quality operations on them before offering them to the analytics team in the most efficient format and with the necessary tools to explore the data.
Throughout the series, you will get the chance to work on most of the tasks that characterize the work of a data engineer, using Apache Spark (the world’s most widely used distributed processing framework) and Delta Lake (one of the most promising and sophisticated open table formats) to build a cloud-based data lakehouse. The end product will be a fully functioning big data pipeline that processes data and pushes it into the different layers of a three-layer data lake. The data will then feed two different interactive dashboards that are running on Apache Superset, the acclaimed open-source BI platform.
Setup Preset Account
Go to https://preset.io/ and Click on “Start for free” button at the top-right corner. Follow the instructions to create a free account there. You can skip the database connection part, we will connect to the database later.
From Data Lake to Lakehouse
In this part, you will use Delta Lake, an open table format and the cornerstone of Databricks’ lakehouse design, to turn our existing data lake into a lakehouse. You will transform the existing tables into Delta tables, explore the features that Delta Lake offers, and witness firsthand how it handles the scenarios and potential issues previously mentioned.
Data Ingestion and Cleaning
Imagine you’re a data engineer working at an enterprise. In this part, you’ll be creating clusters and notebooks, interacting with the Databricks File System (DBFS), and leveraging important Databricks features. You’ll also gain first-hand experience with Apache Spark—the world’s most widely used distributed processing framework—on tasks like reading the input data in CSV and JSON format, filtering, and writing the data to the data lake’s curated layer on DBFS.
Data Manipulation
Step into the role of a data engineer working at an enterprise. Your task is to build a data lake’s serving layer and ensure that business queries run on it in a matter of seconds. You’ll start with reading cleansed data that’s already sitting in the curated layer. Then you’ll transform it, enrich it, aggregate it, and denormalize it using Apache Spark. When you’re finished, you’ll have multiple output tables that make up the serving layer of the data lake.
Interactive Superset Dashboard
At this point, following the work of the first three projects, we have a fully functioning modern lakehouse that’s ready to be queried to generate insights from its data. Our end users want to leverage this data for two different use cases:
- Analytics: This consists of analyzing data aggregates over a long period of time to discover trends and actionable strategic insights and perform an in-depth analysis of historical data.
- Operations/Monitoring: This consists of analyzing recently ingested data to immediately detect issues or anomalies and monitor the health of our business in real time.
As a data engineer, you’re expected to deliver the necessary infrastructure to perform such queries and build dashboards on top of the existing data. In this project, you will use Preset, the SaaS platform that offers a managed version of Apache Superset, to run queries on the lakehouse (via a Databricks cluster) and build two separate dashboards for our use cases.
One of the main advantages of the lakehouse design is that we can rely on it for a wide range of needs and scenarios, including the following:
- Both analytical and operational queries can be performed directly on the lakehouse. Unlike the older data lake design, where we had to maintain data warehouses and data marts on top of the data lake for efficient interactive queries, the lakehouse can be queried directly for various types of use cases thanks to the performance optimizations provided by Delta Lake.
- Delta tables can be used for both batch and streaming ingestion. This means that the same table on our lakehouse can be leveraged for analytical and operational queries.
Throughout the project, you will leverage these characteristics of the lakehouse to query it directly and generate insights from its data.
Follow this link for more information.