Sakila Music Company
The Sakila sample database is made available by MySQL and is licensed via the New BSD license. Sakila contains data for a fictitious movie rental company, and includes tables such as store, inventory, film, customer, and payment. While actual movie rental stores are largely a thing of the past, with a little imagination we could rebrand it as a movie-streaming company by ignoring the staff and address tables and renaming store to streaming_service.
The Sakila was a company that produced classic movies and rented those out of their DVD stores. The DVD rental stores went out of business years ago, but the owners have now made their classic movies available for purchase and rental through various streaming platforms.
The company receives information about their classic movies being streamed from their distribution partners in real time, in a standard format. Using KDG, we will simulate the streaming data that's received from partners, including the following:
- Streaming timestamp
- Whether the customer rented, purchased, or watched the trailer
- film_id that matches the Sakila film database
- The distribution partner name
- Streaming platform
- The state that the movie was streamed in
For Batch data - Load data into RDS MySQL, Create AWS Data Migration Service Endpoints, Replication Instances and Tasks, Start the Task, Verify the Ingestion with Athena. For Stream data - Create Kinesis Firehose, Create Kinesis Data Generator and Push data to Firehose, Create and run Glue crawler on the streamed file in S3 and verify the ingestion with Athena.
Data Migration
Batch and Streaming Data Pipeline in AWS
In most organizations, there are also likely to be multiple environments, such as a development environment, a test/quality assurance (QA) environment, and a production environment. The data infrastructure and pipelines must be deployed and tested in the development environment first, and then any updates should be pushed to a test/QA environment for automated testing, before finally being approved for deployment in the production environment.
In the following diagram, we can see that there are multiple teams responsible for different aspects of data engineering resources. We can also see that the data engineering resources are duplicated across multiple different environments (which would generally be different AWS accounts), such as the development environment, test/QA environment, and production environment. Each organization may structure its teams and environments a little differently, but this is an example of the complexity of data engineering in real life:
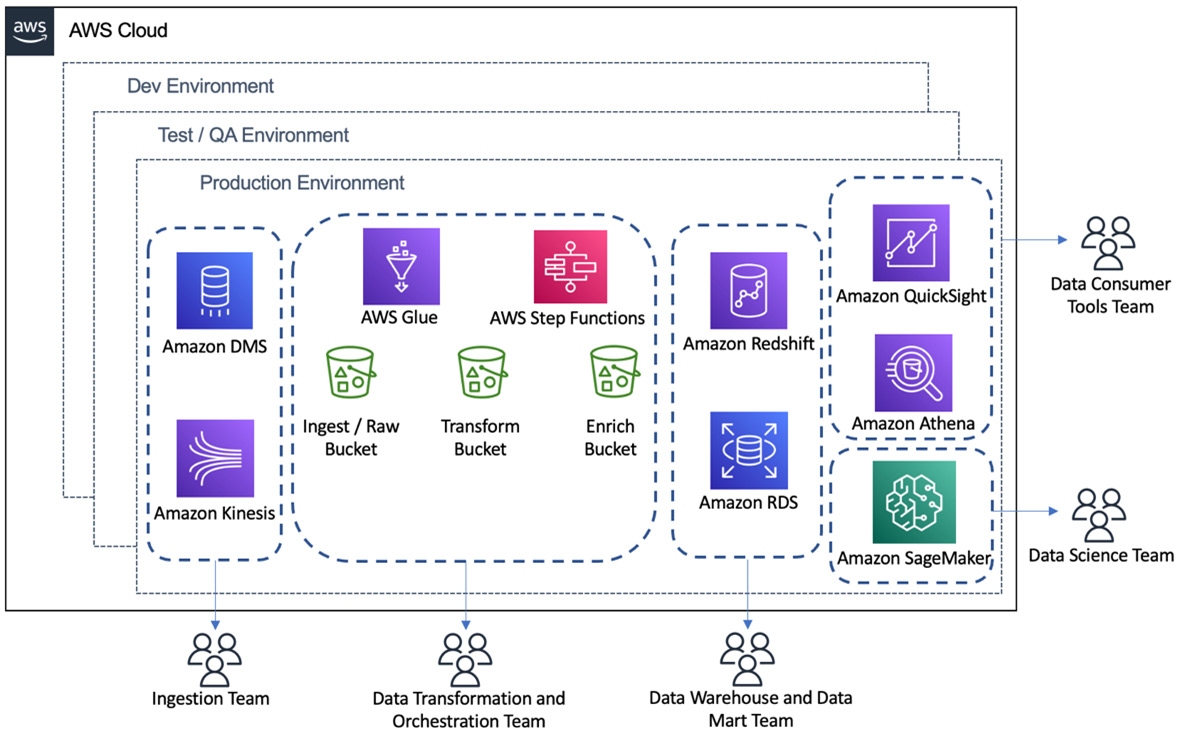
It is a challenge to work in these kinds of complex environments, and an organized approach is required to be successful. Part of understanding the bigger picture of data analytics is to understand these types of challenges and how to overcome them.
References
Using a MySQL-compatible database as a source for AWS DMS
Using Amazon S3 as a target for AWS Database Migration Service