Data Warehousing with Amazon Redshift
Taxi Data Process and Save to Redshift using AWS Wrangler
pip install psycopg2-binary awscli boto3 awswrangler
import os
import boto3
import json
from time import time
import psycopg2
import pandas as pd
from sqlalchemy import create_engine
import awswrangler as wr
SECRET_NAME = "wysde"
URL = "https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-01.parquet"
INFILE = "yellow_tripdata_2022-01.parquet"
S3_PATH = "s3://wysde/taxi"
DB_NAME = "dev"
TABLE_NAME = "yellow_tripdata_2022_01"
CONN_NAME = "aws-data-wrangler-redshift-dev"
CONN = wr.redshift.connect(CONN_NAME)
os.system(f"wget {URL} -O {INFILE}")
wr.s3.upload(local_file=INFILE, path=S3_PATH+"/"+INFILE)
dfs = wr.s3.read_parquet(path=S3_PATH+"/"+INFILE, chunked=100000)
for df in dfs:
df.tpep_pickup_datetime = pd.to_datetime(df.tpep_pickup_datetime)
df.tpep_dropoff_datetime = pd.to_datetime(df.tpep_dropoff_datetime)
wr.redshift.copy(
df=df,
path=S3_PATH+"/"+INFILE,
con=CONN,
schema='public',
table=TABLE_NAME,
mode="upsert",
primary_keys=["VendorID"]
)
Connect to Amazon Redshift Cluster using Python
pip install psycopg2-binary
import pandas as pd
import psycopg2
import boto3
import json
from sqlalchemy import create_engine
from sqlalchemy import text
def get_secret(secret_name='wysde'):
region_name = "us-east-1"
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=region_name)
get_secret_value_response = client.get_secret_value(SecretId=secret_name)
get_secret_value_response = json.loads(get_secret_value_response['SecretString'])
return get_secret_value_response
secret_vals = get_secret()
redshift_endpoint = secret_vals['REDSHIFT_HOST']
redshift_user = secret_vals['REDSHIFT_USERNAME']
redshift_pass = secret_vals['REDSHIFT_PASSWORD']
port = 5439
dbname = "dev"
engine_string = "postgresql+psycopg2://%s:%s@%s:%d/%s" \
% (redshift_user, redshift_pass, redshift_endpoint, port, dbname)
engine = create_engine(engine_string)
query = """
SELECT *
FROM pg_catalog.pg_tables
WHERE schemaname != 'pg_catalog' AND
schemaname != 'information_schema';
"""
df = pd.read_sql_query(text(query), engine)
query = """
SELECT * FROM "dev"."public"."users";
"""
df = pd.read_sql_query(text(query), engine)
Implement a slowly changing dimension in Amazon Redshift
Follow this tutorial.
This tutoiral walks you through the process of implementing SCDs on an Amazon Redshift cluster. It goes through the best practices and anti-patterns. To demonstrate this, it uses the customer table from the TPC-DS benchmark dataset. It shows how to create a type 2 dimension table by adding slowly changing tracking columns, and go over the extract, transform, and load (ETL) merge technique, demonstrating the SCD process.
The following figure is the process flow diagram:
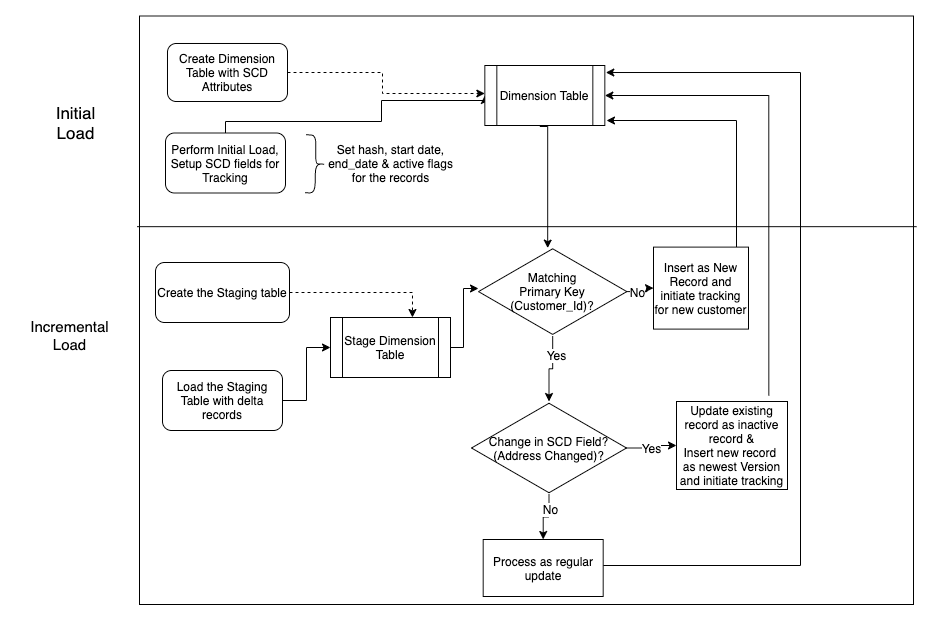
The following diagram shows how a regular dimensional table is converted to a type 2 dimension table:

Create a Cluster using CLI
Use the following command to create a two-node dc2.large cluster with the minimal set of parameters of cluster-identifier (any unique identifier for the cluster), node-type/number-of-nodes and the master user credentials. Replace $MasterUserPassword in the following command with a password of your choice. The password must be 8-64 characters long and must contain at least one uppercase letter, one lowercase letter, and one number. You can use any printable ASCII character except /, "", or, or @:
aws redshift create-cluster --node-type dc2.large --number-of-nodes 2 --master-username adminuser --master-user-password $MasterUserPassword --cluster-identifier myredshiftcluster
It will take a few minutes to create the cluster. You can monitor the status of the cluster creation process using the following command:
aws redshift describe-clusters --cluster-identifier myredshiftcluster
Note that "ClusterStatus": "available" indicates that the cluster is ready for use and that you can connect to it using the "Address": "myredshiftcluster.abcdefghijk.eu-west-1.redshift.amazonaws.com" endpoint. The cluster is now ready. Now, you use an ODBC/JDBC to connect to the Amazon Redshift cluster.